How top data teams are structured

Note: You can explore all the data of this analysis here: databenchmarks.com
As the scope of data teams has increased, so has the number of people working in them. That’s mostly great—data teams now drive business-critical data products and go beyond answering ad hoc questions. But it also warrants questions such as “Do we have the right balance between investing in our foundations and insights” and “Are we operating as efficiently as our peers given the outcomes we achieve”.
This post looks at the distribution of data roles within 40 top data teams in the US and Europe to help you answer these questions.
Data roles categorization
There’s no shortage of different names for data roles. While data work is not constrained to specific job titles, it can most often be categorized into the following groups.
- Insight – Data Analysts, Product Analysts, Data Scientists
- Data Engineering – Data Engineers, Data Platform Engineers, Analytics Engineers, Data Governance
- Machine Learning – Machine Learning Engineers
Data team roles are often vague, making it hard to compare across companies and even harder for job seekers to understand expectations. For example, some companies use the data scientist title for people working with research and machine learning, while others have entirely replaced the analyst title with data scientist.
Companies have many people in analyst roles, such as financial and credit analysts. These people typically sit outside the data team, so in our analysis, we’ve only included data and product analysts as belonging to the data team. People in machine learning roles are also hard to categorize. Some companies have machine learning reporting lines under engineering, while others have them report to the data organization. For simplicity, we’ve categorized machine learning roles as belonging to the data team.
Data role composition at top companies
A common topic of discussion is the ratio between people in insights roles and people in data engineering roles. If you over-index on insights roles, you may risk slowing everyone down as the quality of the data platform starts to deteriorate. If you over-index on data engineers, you may have a world-class data platform but no insights or data products that drive business impact to show for it.
Across the 40 data teams we’ve looked into, the median proportion of people in insights roles is 46%, slightly higher than the 43% in data engineering roles.
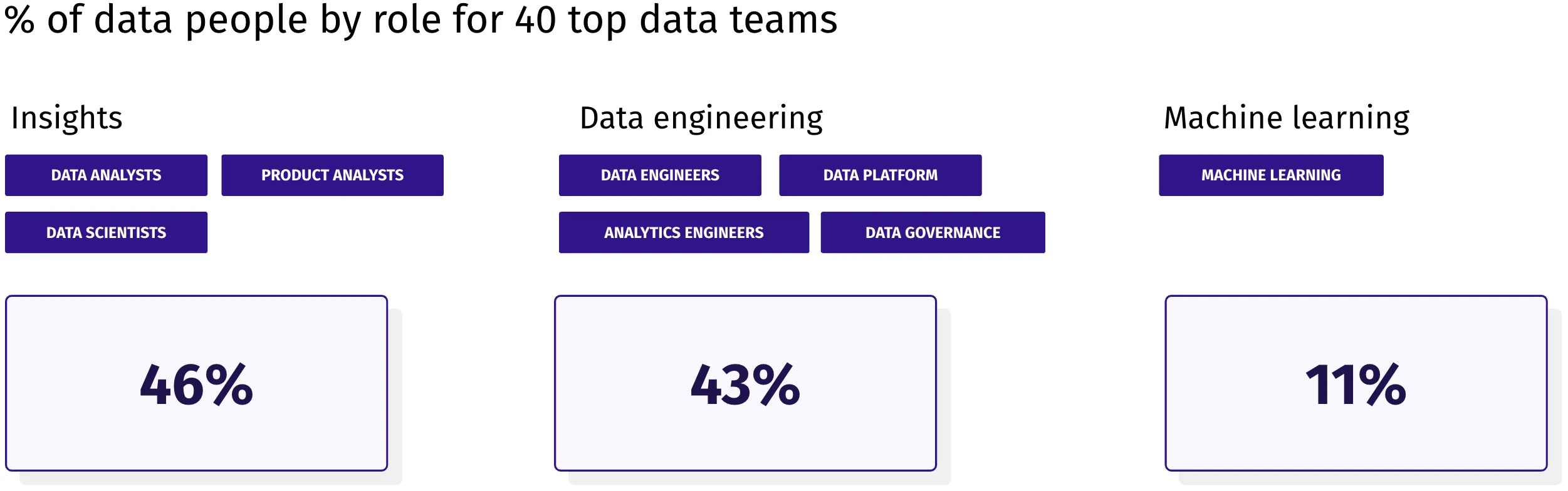
These numbers vary significantly by company. Part of this is semantics. Some companies avoid using analysts and refer to everyone as a data scientist. Others have different boundaries for where data and analytics engineers’ work begins and ends. Thus, a company with a low proportion of analytics engineers is not necessarily investing less in data modeling. This work may just be ingrained in the day-to-day work of analysts.
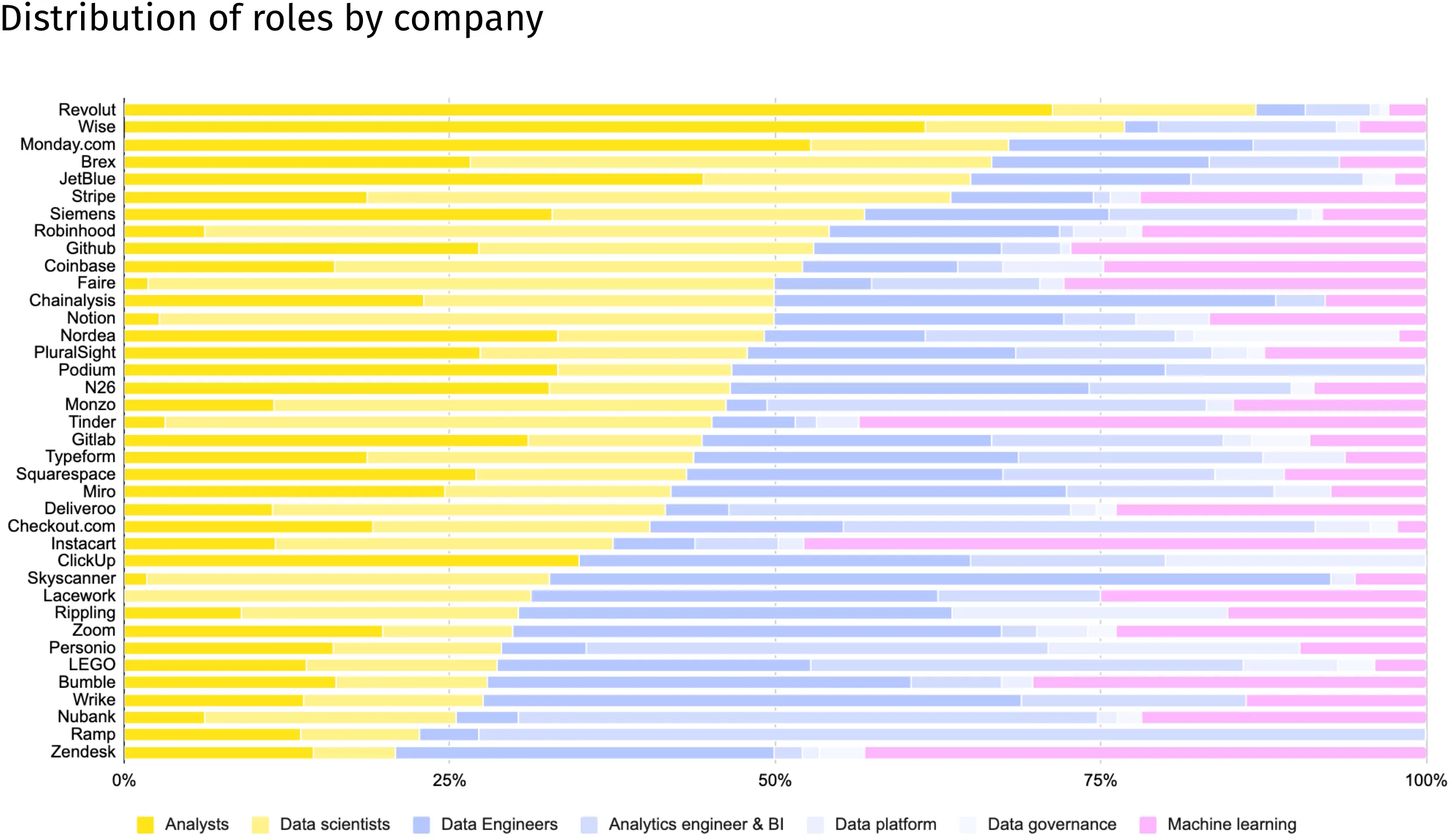
Deep dive into the data used here: databenchmarks.com
We only have to look at a few examples to see the caution you have to show when comparing companies. These also highlight that the optimal ratio may vary significantly depending on the company’s priorities.
- Revolut has a large share of analysts, many of whom are distributed across different markets and working on areas such as financial crime and credit.
- Zendesk has a large machine learning team in line with the company’s recent refocus to “the world’s most complete CX solution for the AI era”
- Nubank now refers to all data analysts as analytics engineers to demonstrate its focus on better applying established software engineering principles and data modeling techniques to all business domains.
To expand on this, see the following articles: Data team as % of workforce: A deep dive into 100 tech scaleups and data and product to engineer ratio at 50 tech scaleups.
Data team composition by company size
Company priorities vary by size. Growth stage companies may focus on optimizing decision speed and supporting new product launches. A more mature company that recently went through an IPO may focus more on accurate reporting, compliance, and security.
We can segment companies into different groups to look more into how this varies by company size.
- Mid–growth stage companies with a data team smaller than 35 (e.g., Typeform, Brex, and Personio)
- Large–scaling companies, often approaching an IPO with a data team of 35-100 (e.g., Notion, Miro, and N26)
- Scale–larger scaleups, public companies, and large enterprises with a data team of 100+ (e.g., Zendesk, LEGO, and Nubank)
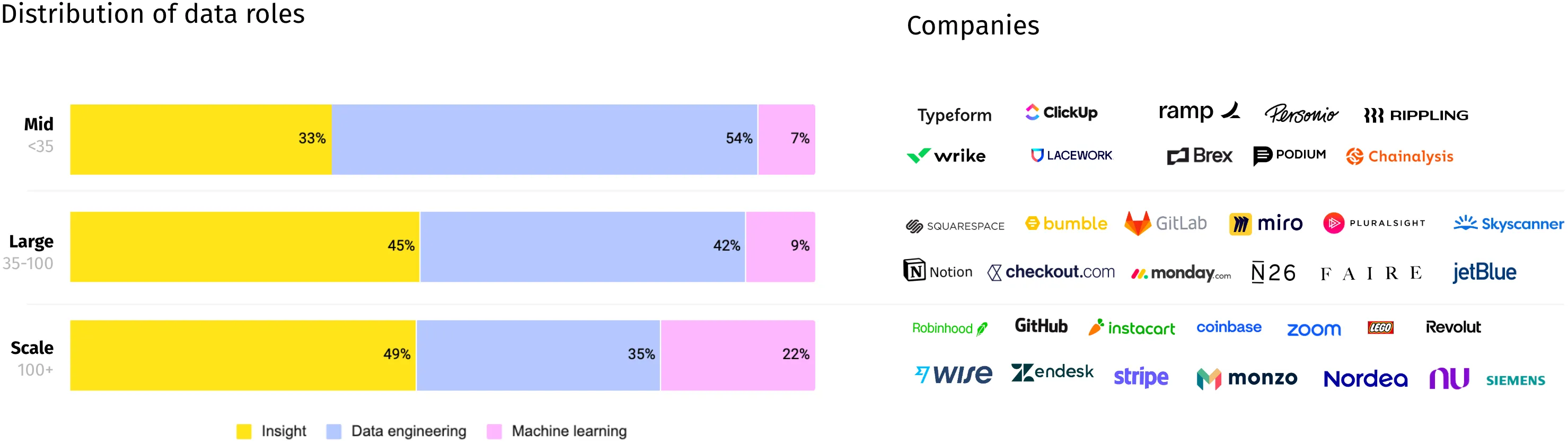
Two things stand out:
- Mid-size data teams have a notably higher share of people in data engineering roles. This may indicate that a core platform is needed for analysts and engineers to work on, but insights may also be more frequently done by people outside of the data team, such as product managers and engineers.
- Scale companies have a significantly higher share of people in machine learning roles. In our research, one explanation for this is that they’re more likely to have found product-market fit with their machine learning implementations and be able to show clear ROI. This means that what started as small experimental teams now require larger teams for upkeep and continued investments.
Finally, 60% of the scale segment has a data governance function compared to 20% for everyone else. This fits their maturity level, typically requiring a structured approach to managing DataOps.
Wrap up
We’ve looked into the distribution of data roles in 40 top data teams. To make the comparison as simple as possible, we categorized data roles into three groups: Insights (Data Analysts, Product Analysts, Data Scientists), Data Engineering (Data Engineers, Data Platform, Analytics Engineers, Data Governance), and Machine Learning (Machine Learning Engineers).
The median proportion of people in each group is 46% for Insights, 43% for Data Engineering, and 11% for Machine Learning roles. These numbers should be taken with a grain of salt, as definitions of data roles vary significantly by company. We also conclude that no one-fits-all ratio works for all companies, but the best ratio can vary significantly depending on company priorities, maturity stage, and size.


