How Ebury Created Scalable Regulatory Data Products with SYNQ
Building a scalable data mesh setup with best-in-class regulatory reporting.
Data at Ebury
Ebury, a global fintech company specializing in cross-border trade with offices across 29 markets, manages a sprawling data ecosystem. Data is key for central business processes such as models to assess customer risk and reports delivered to regulators. Their stack includes nearly 9,000 BigQuery tables, over 6,000 dbt models, and more than 5,500 dbt tests, supported by hundreds of Looker dashboards.

Key challenges
- Lack of visibility into data dependencies: Failures in early pipeline stages often left teams guessing about downstream impacts, creating uncertainty around whether critical regulatory reports were impacted.
- Scattered data ownership: A monolithic architecture with unclear accountability slowed issue resolution and complicated collaboration between the data team and business stakeholders.
- Regulatory compliance risks: Ensuring data accuracy for FCA and other regulatory bodies required demonstrating robust model testing, lineage, and governance—a growing challenge with their expanding data scale.
“For model validation, we need to escalate issues to the risk committee before they impact decisions. Not knowing whether our data is reliable isn’t an option. This also applies to regulatory reporting” – Prado Morón, Head of Model Risk Governance.
Solution: Adopting data products as the key pillar to build reliable data
To address these challenges, Ebury turned to SYNQ to introduce structure and clarity to their data operations. The team leaned into a data product framework to transition from a monolithic data architecture to a data mesh inspired domain-driven approach. This allowed teams to take ownership of specific data products, aligning closely with business goals.
Data products are grouped into domains such as Credit Risk and Treasury. “This overview gives responsible domain owners across the data and business teams all the details they need to know without keeping the context of thousands of irrelevant assets in their head,” says Maria Samper, Data Platform Engineering Lead.
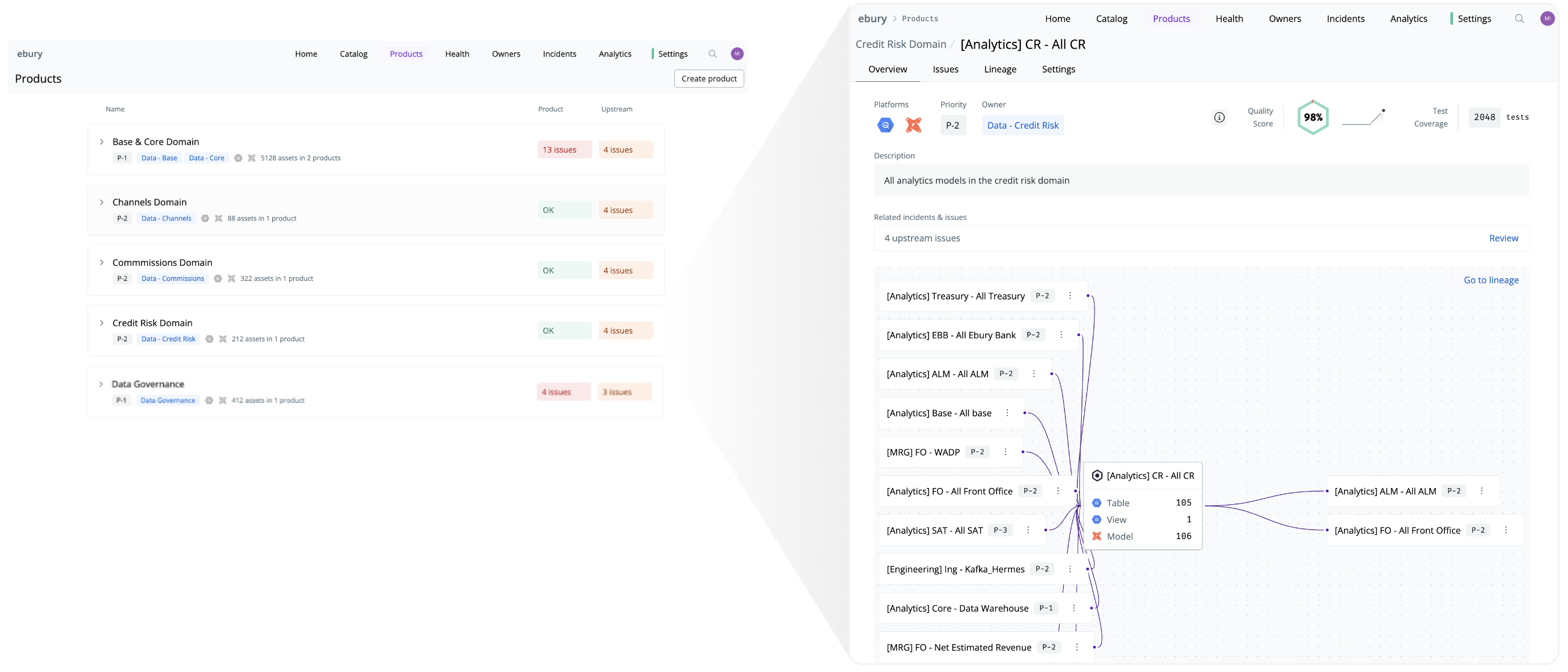
“We now look at the health of our data through the lens of a few dozen data products and can immediately see if there are any issues and who’s impacted. Before using data products, this was close to impossible as we had to manage and understand the state and dependencies across many thousands of tables”
Key steps included:
- Automated monitoring on critical models: Using SYNQ’s integration with dbt, they tagged “critical” models in dbt yml files to ensure high-priority assets automatically have the relevant anomaly monitors applied, reducing noise and focusing efforts where they matter most.
- Activating ownership definitions: Teams receive domain-specific notifications based on ownership definitions that combine data products and specific folders in dbt. This enables faster resolution of issues. Analysts now check SYNQ daily for updates relevant to their data products and get alerted directly in Slack.
- Business alerts to non-technical stakeholders: Some issues are best solved directly by business teams owning the source systems. Ebury has created specific tests to catch these types of issues and send “business alerts” from SYNQ that can be understood by business teams without any context about the data stack.
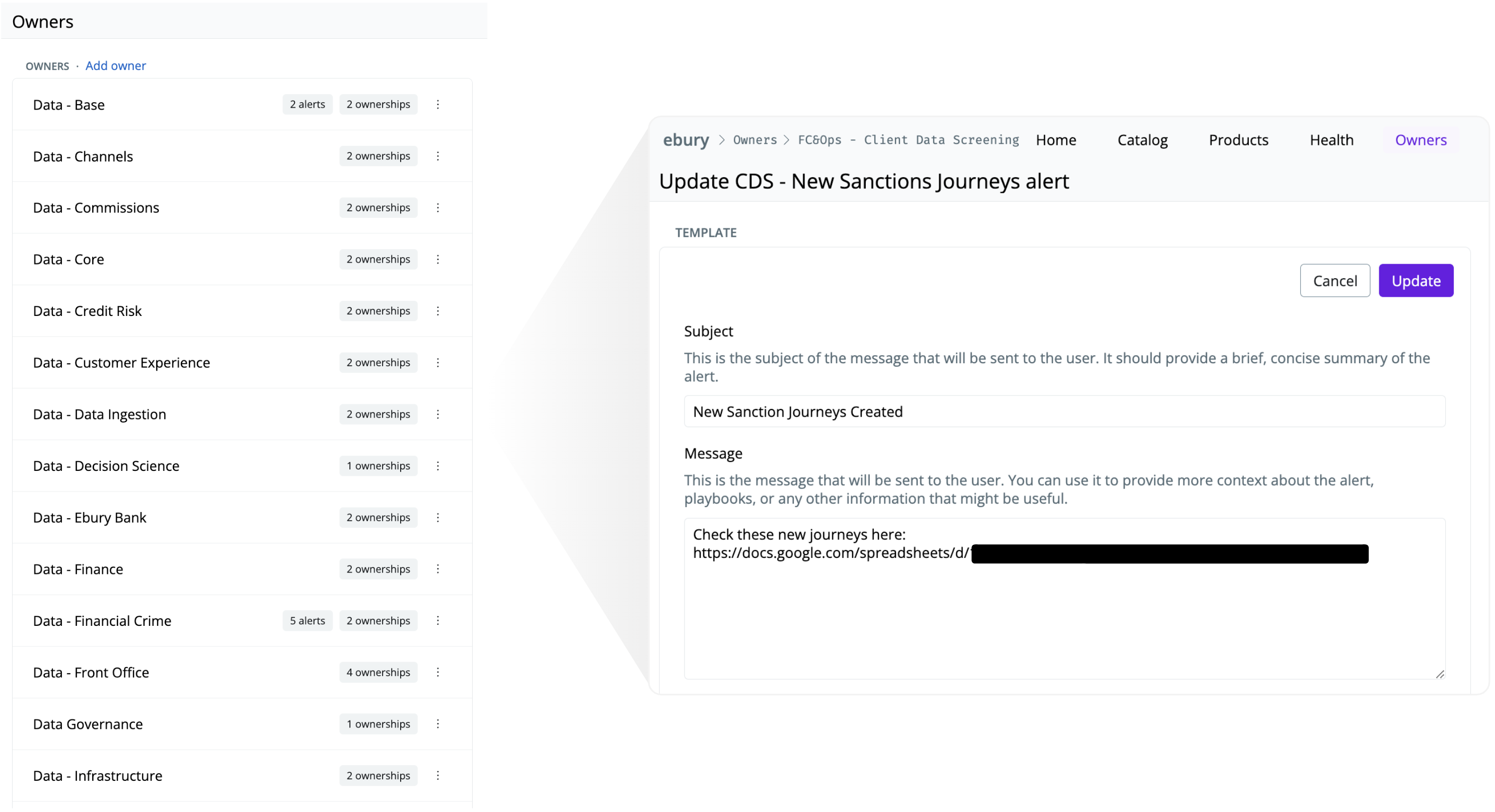
“SYNQ provides us with a full overview of what needs validation, considering all upstream and downstream use cases. Our data product and ownership groupings make it easy to see exactly what and who is impacted. This clarity has been instrumental in scaling our operations,” says Maria Samper.
Before and after–transitioning to a data mesh
Ebury’s move from a centralized model to a data mesh has been transformative. Before SYNQ, two engineers were responsible for monitoring the entire pipeline—a nearly impossible task given the scale. Now, domain-specific ownership means teams monitor and resolve issues within their areas of responsibility.
“The shift has been essential for aligning business and technical teams. SYNQ has helped us implement a data mesh strategy where ownership and accountability are embedded into every process. Each week, at least 25 analysts log in and use SYNQ,” says Prado Morón.
Another benefit of the data mesh setup is that the central data platform and model governance team can look back at the data quality performance tracking metrics such as new and resolved issues and test coverage, segmentable by key dimensions such as owner, data product, and criticality. “Before SYNQ, I had to spend many hours each week stitching together reports from different systems in a spreadsheet – at scale, this would have been impossible to maintain,” says Prado Morón.
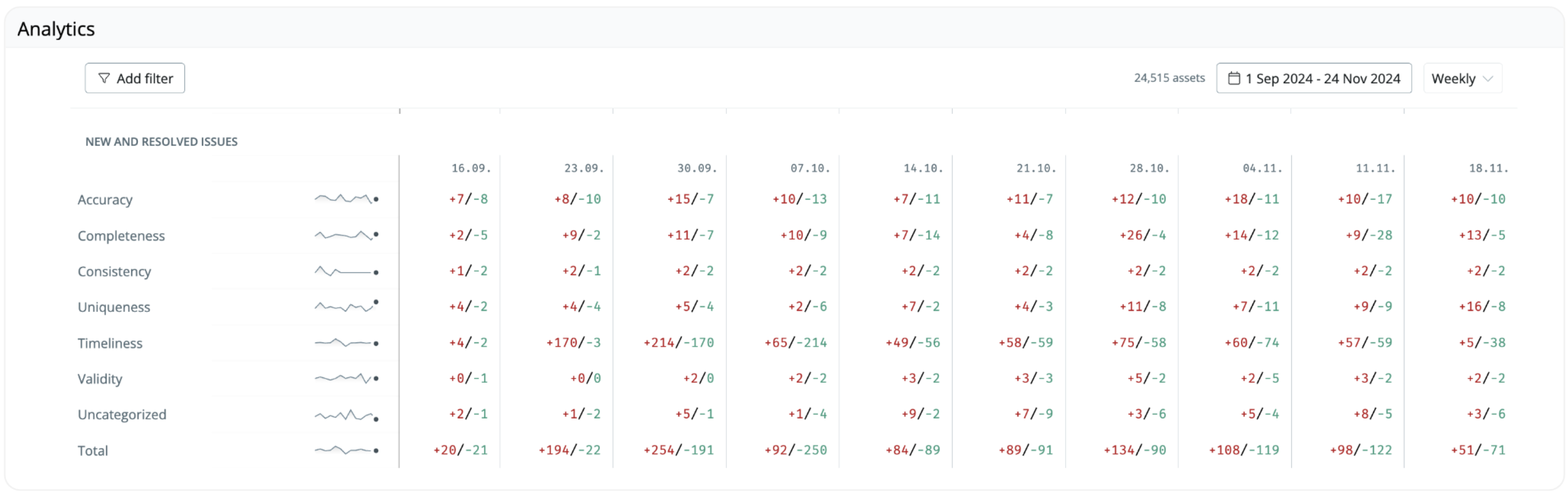
“Data products have become the backbone of our entire data operations – from managing where we place monitors, to how we define and activate ownership, and look back on metrics to systematically improve our data quality”
Results: A scalable data mesh setup with best-in-class regulatory reporting
With SYNQ, Ebury has made significant improvements:
- Reduced time to resolution: By organizing data into dozens of domain-specific products, ownership has been clarified and issues are brought directly to the relevant owners across the data or business teams significantly reducing issue resolution times.
- Reduced critical issues: From exposing the downstream dependencies through the lineage, and showing impacted data products and owners, the data team is instantly aware of any major downstream impact – a significant improvement for ensuring accurate regulatory reporting.
- Reduced alert overload: By using dbt tags to programmatically add anomaly monitors only on critical models, the number of false alerts and unnecessary noise has been reduced, empowering teams to prioritize effectively.
- Improved regulatory reporting: The model governance team can now demonstrate SLA adherence, model validation, and robust data governance practices, reducing compliance risks.
One key success came from identifying missing data filters in regulatory pipelines. SYNQ’s automated monitors helped us identify the issue within minutes and act on it before any issues escalated. Similarly, freshness and volume monitor flagged delays in currency conversion rates—critical for our operations—which we resolved before it caused a significant downstream impact.
Next Steps: Scaling data governance and discoverability
Ebury’s next step is to scale their data governance initiatives while using SYNQ as the backbone for data reliability. With nearly 9,000 tables, scalability and discovery have become a larger challenge for stakeholders across the company. Therefore, Ebury is evaluating data catalog tools for a second-line governance framework and data discovery. A key priority is the tool’s ability to send and receive data from SYNQ to create a transparent glossary of the status of all data assets.
“SYNQ’s seamless integration with our stack—BigQuery, dbt, and Looker—has been a game-changer. We evaluated several data observability tools and SYNQ by far had the most comprehensive dbt integration. It aligns with our strategy to scale data governance without deviating from existing analytics engineering workflows,” Maria Samper says.
Build with data you can depend on
Join the data teams delivering business-critical impact with SYNQ.