Dext achieved end-to-end visibility across multiple dbt projects with SYNQ
How dbt combined with a data observability tool helped Dext reduce resolution times by 30%
About Dext
Dext is the advanced bookkeeping automation platform that eliminates much of the manual work that slows bookkeepers and accountants down. The platform reduces the time it takes to capture, code, publish, and reconcile invoice and expense data, giving them more time to add value and grow.
The challenge: Crossing the chasm between data engineers and analytics across multiple dbt projects
Data is instrumental in all decisions at Dext, from general managers making decisions on week-to-week market strategies based on MRR data to the C-level planning of new market expansions and product categories. Delivering on this requires a well-oiled data stack and thousands of data assets.
Silos due to the organisational structure
For a long time, the data team was divided into two separate departments: Data Engineering within the Engineering department, focusing on delivering data pipelines and ensuring scalability, performance, and reliability, and Analytics within the Finance department, helping business leaders make data-driven decisions. This siloed structure led to the use of different tools, processes, and priorities between the two groups.
Early on, the Analytics team identified a gap for better data workflows, such as improved code maintainability, collaboration, and deployment. To address this, the team implemented dbt while the Data Engineering team continued with their existing setup using PySpark for ETL.
No visibility across dbt projects
As the company moved to Snowflake, the Data Engineering team also adopted dbt. To make managing thousands of data models easier, the teams split their stack into two dbt projects: (1) Data Lake dbt, ingesting raw data from events, and (2) Analytics dbt, transforming data and creating final marts. While this approach simplified the segregation of data between the Data Engineering and Analytics teams, it posed challenges for everyone involved in tracing back the root cause of issues.
“As a data analytics engineer, my role involves ensuring the integrity, accuracy, and accessibility of our data. Data management is central to this, encompassing everything from data ingestion and processing to analysis and reporting.”
The most imminent challenge Dext faced was getting a best-in-class data lineage that fit the stack and supported a multi-project dbt setup. The team debated building this in-house but quickly realised they would have to build many internal tools, such as custom alerting, testing, and lineage, and decided to look for a data observability platform instead.
The solution: Cross-project lineage tightly integrated with dbt workflows
Automated lineage across multiple dbt projects
A key capability the team at Dext was looking for was automated lineage spanning the data warehouse and Looker. The team tried maintaining exposures in dbt, but this was not scalable with 500 dashboards and thousands of data models. It was a key requirement that the lineage had deep support for dbt, including the ability to display the status of the nodes directly in the lineage and map the lineage across multiple dbt projects without the need for tedious cross-project references.
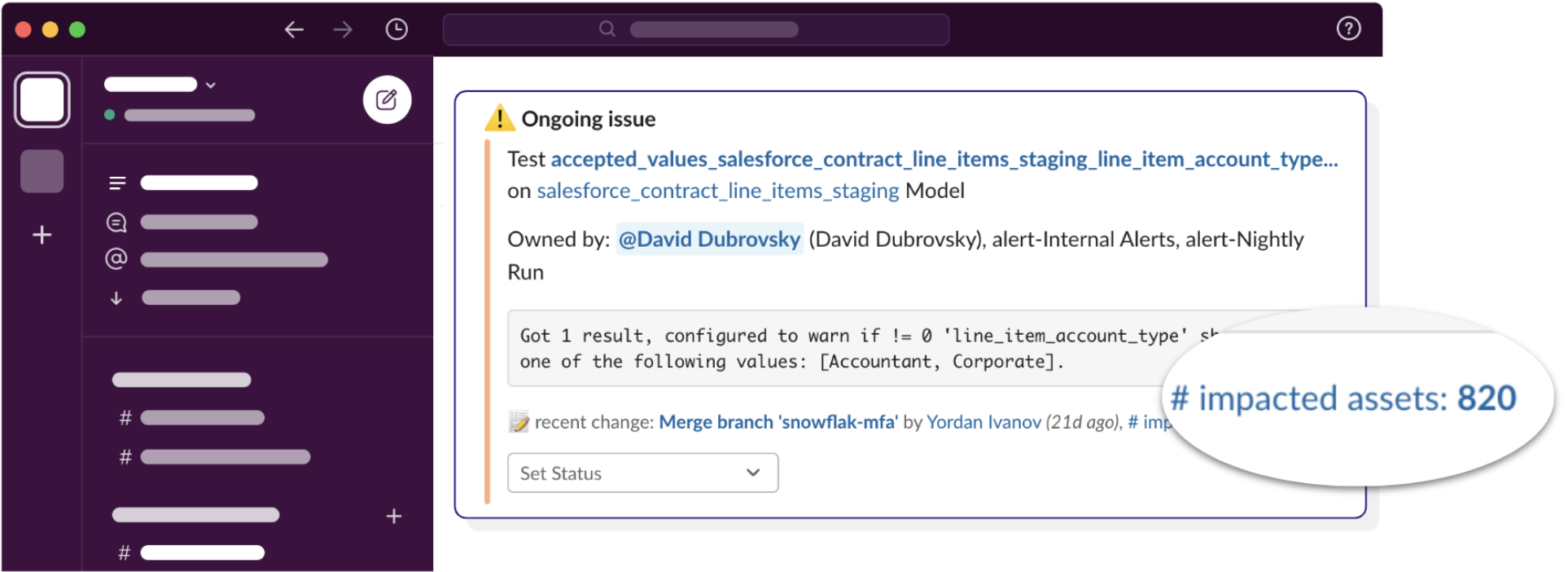
“We recently faced a complex issue where data discrepancies appeared in our BI reports. With SYNQ, we could quickly trace the issue back to its source across multiple dbt projects, saving us many hours of manual investigation and significantly reducing the resolution time.”
SYNQ’s automated data lineage eliminates the need for manually maintained exposures and provides an integrated view that includes the status of nodes and the mapping of lineage across projects. This helps the team work more efficiently when tracing issues across teams and resolving issues faster.
Introduction to SYNQ’s cross project lineage (1 minute and 30 seconds)
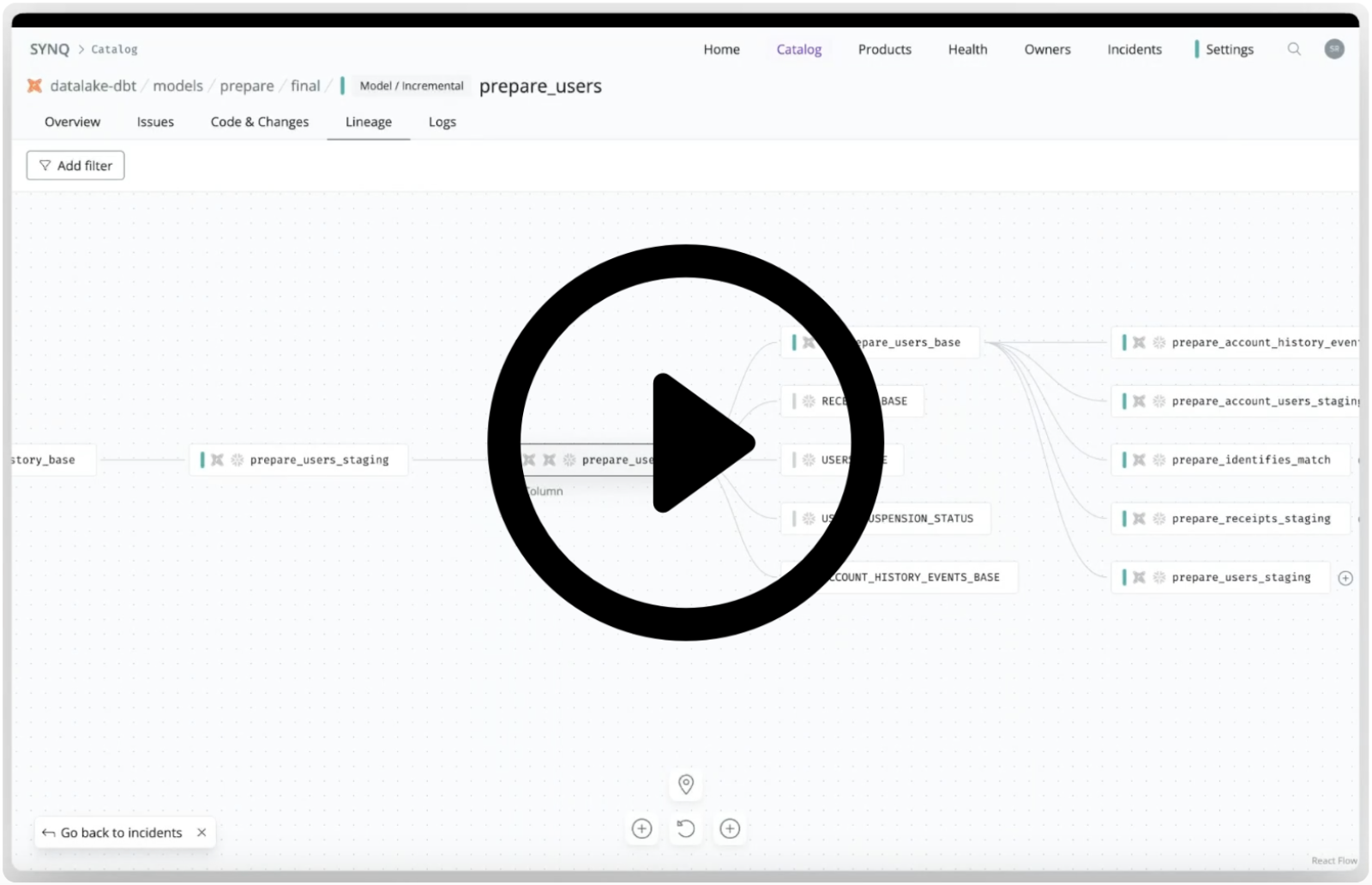
How SYNQ’s lineage works
Under the hood, SYNQ fetches lineage from each tool separately. From dbt, it gathers data via the artifacts. From BI tools, it utilises APIs or parses LookML. From data warehouses, it combines extracted table DDL and query logs. SYNQ uses Abstract Syntax Trees (ASTs) to comprehensively build and understand the lineage.
SYNQ constructs a graph for each tool by internally abstracting and modelling the assets. It identifies nodes where lineage between tools connects, such as a dbt model creating a data warehouse table, allowing SYNQ to overlay and integrate these lineages into a cohesive overview. With column-code lineage, SYNQ extracts the location of tokens and precisely understands the flow of logic through SQL files.
In multi-dbt project environments, one project often sources outputs from another. SYNQ resolves this lineage automatically via the underlying data platform’s lineage, eliminating the need for foreign references or special constructs.
”Maintaining separate dbt projects has provided us with several key benefits,” says Yordan.
- Focused Concerns: By maintaining distinct dbt projects, the Data Engineering team can focus on the technical aspects of data pipelines, such as data transformation, data quality, and infrastructure, without burdening the Analytics team’s specific requirements. Similarly, the Analytics team can concentrate on business-oriented data modelling, reporting, and analysis without being distracted by the technicalities of the underlying data engineering processes.
- Iterative Development: The separate dbt projects allow each team to iterate on their goals at different speeds without the need to synchronise changes or risk disrupting the other team’s workflows. This flexibility enables both teams to respond more effectively to changing business requirements and technological advancements.
- Organisational Alignment: The microservices-inspired approach of having two dbt projects aligns with our team’s organisational structure, where Data Engineering and Analytics have been historically separated. This alignment helps to maintain clear roles, responsibilities, and decision-making processes within the data team.
- Reduced Complexity: Keeping the Data Engineering and Analytics concerns separate prevents the potential complexity and noise arising from a single, monolithic dbt project. This simplifies the overall data architecture and makes it easier to manage, maintain, and scale the data processes over time.
Field-level lineage extending beyond what Snowflake offers
A key question to answer with the data lineage was understanding the ‘blast radius’ of changing a field to know the downstream impacted assets. The ability to do this across dbt and Looker – where data is consumed – was a significant gap.
“Due to the complexity of our data stack, it’s not uncommon for a data model to have hundreds of downstream models depending on it. Table-level lineage was good for giving a finger-in-the-air estimate of the impact, but the column-level lineage helps us much more accurately assess the impact,” says Yordan. It has also reduced the errors introduced by the Data Engineering team. Through cross-dbt project lineage, everyone can understand the impact of changing a field, from the Data Lake project down to the Looker dashboards it uses.
“SYNQ has improved our collaboration by providing a transparent view of our data lineage that is accessible to our team and non-technical stakeholders. This shared understanding helps us work more effectively on data-related projects and issues.”
Tightly coupled dbt workflows
Dext weighted a deep level of dbt support as one of the top parameters when selecting its data observability platform, as dbt is the workhorse for all data modelling.
“One example of how well SYNQ fits into our dbt workflows is that they now power all our alerts. Each alert links to the lineage, showing all downstream impacted assets across both our dbt projects and Looker,” says Yordan.
”The most valuable aspect is its visibility into our data ecosystem. Understanding how data flows and transforms is crucial for maintaining data quality and making informed decisions in complex environments. SYNQ automates this process, providing instant insights into our data lineage.”
The outcome: Reduced time to resolution by 30%
“Since we started investing in our Data Engineering workflows at the beginning of 2023, we’ve seen a notable change in our ability to make changes more quickly and confidently. This has significantly reduced the issues and data discrepancies our stakeholders discover in Looker,” says Yordan. Another benefit is that resolution time has been notably reduced. Issues that would have taken many hours to trace back can now be resolved in minutes.
“Part of it can be tailored to specific metrics, but the biggest change is the cultural shift we’ve seen in the data team,” says Yordan.

“ We are much faster at identifying the root cause of data discrepancies. We recently corrected a significant reporting error impacting our sales forecasts. This correction led to more accurate forecasting and better strategic decisions."
"SYNQ’s automated data lineage has been a game-changer. It has significantly reduced the time we spend tracing data lineage, allowing us to focus more on analysis and insights. It has also improved our data quality by enabling faster identification and resolution of data issues.”
Build with data you can depend on
Join the data teams delivering business-critical impact with SYNQ.