Aiven enhances dbt with SYNQ to build reliable data products
How switching data observability platform helped Aiven’s data team achieve a unified issue management workflow
About Aiven
Founded in 2016, Aiven is a trusted data and AI platform company, helping organizations gain more value from their data. Aiven’s cloud platform combines open source services to stream, store, and serve data, simply, securely, and rapidly across major cloud providers to power innovation. Aiven is trusted by thousands of customers globally to create next-generation applications confidently and quickly.
The challenge
Aiven takes a data-first approach to decision-making, so timely, accessible, and accurate data is a top priority. The executive leadership team across departments at Aiven rely on data from the data warehouse for weekly business reviews. The data must be accurate for reporting because it impacts decisions made for the business. “If we report wrong numbers, decisions could be made to misallocate budget to the wrong areas, and it could be too late to change course,” says Stijn, Aiven’s Data Engineering Manager.
The data team at Aiven had adopted dbt but was aware they still had blindspots that weren’t covered by tests. They decided to adopt a data observability platform early on to be ahead of the game.
“Without a data observability tool, we’re flying blind. One of our engineers recently changed extraction logic from an internal data source, resulting in lost historical information on previously deleted rows. The dbt tests didn’t catch it, but SYNQ flagged it as an anomaly. In another case, we changed the materialization logic of a Snowplow table causing a drop in the data during the incremental load process. This had a huge impact on all downstream use cases. SYNQ quickly caught this, allowing us to proactively approach stakeholders and deploy a fix within an hour,” says Stijn.
Aiven identified gaps with their existing data observability platform
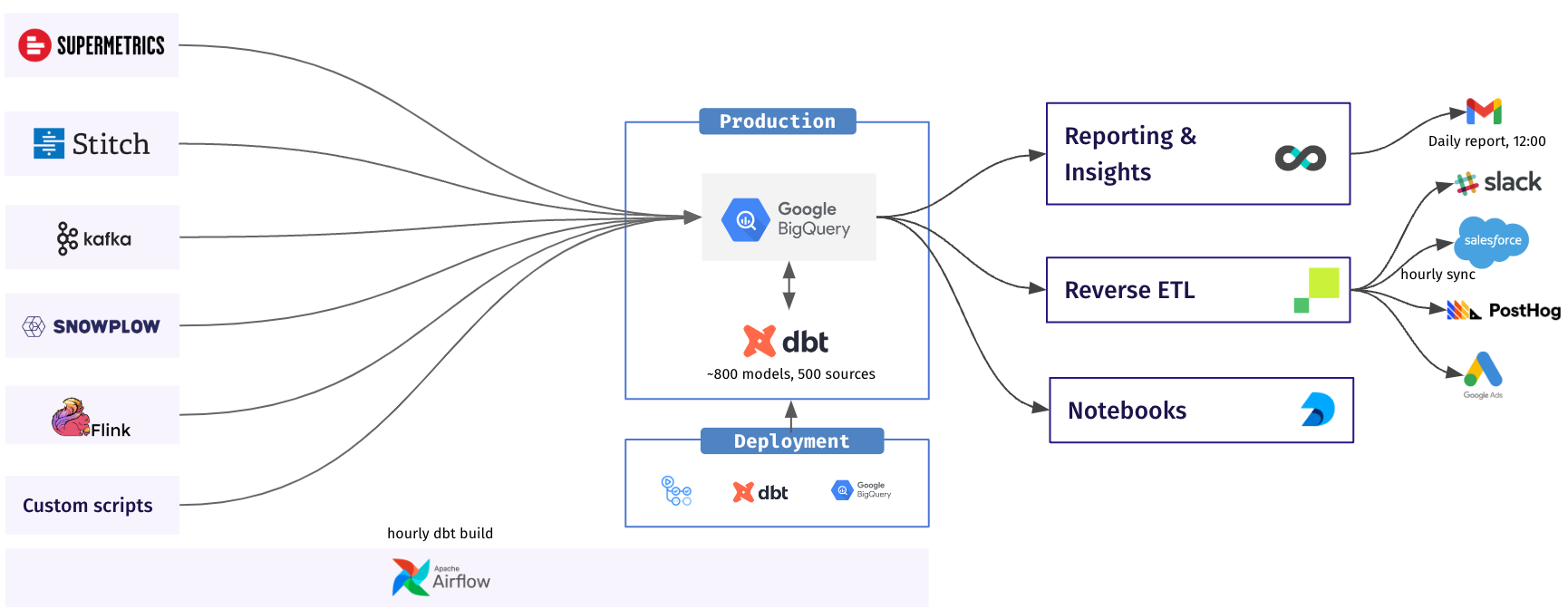
“Having already used a data reliability platform for a year before switching to SYNQ, we knew the ROI was there and that we wanted a tool in place, but our existing provider didn’t fit key workflows,” says Stijn. The team identified four gaps to cover when assessing their new provider.
- Deep dbt integration: On the surface, the existing data observability platform had an integration with dbt, but it lacked depth. The team couldn’t customize how they got alerted about dbt test errors in Slack, meaning they’d get alerted about the same issue repeatedly. Another gap was the ability to link data assets to trace back if an anomaly monitor and a dbt test failing indicate the same issue. Finally, the previous data observability provider charged extra to include the dbt integration.
- Unified ownership model: The data team at Aiven could previously only route issues to different channels, which didn’t work well for their setup. Instead, they needed the ability for multiple individuals to be assigned ownership of assets and then be tagged in the same Slack channel to avoid having to look through many different channels. “Our ambition is to distribute ownership to the analysts, and to fetch that information from dbt metadata to fit existing workflows.”
- Distinguishing issues and incidents: The previous provider treated all issues as incidents. But for the Aiven data team, an incident is very different from an issue. “We needed the ability to declare incidents to help us focus on what’s most important. An issue and an incident are two different situations. We needed to have a way to declare incidents and count the number of incidents over time to see if we are improving. This is impossible when indicents and issues are mixed since there are too many false positives.”
- UI & ease of use: A problem with the previous observability platform was the overwhelming number of options for configuring it, which made the tool hard to use. That meant it was hard to ramp up and inaccessible to the broader data team. Moreover, many configurations were not optimized by default. “We wanted a tool that focused on ease of use and had an opinionated stance on best practices,” says Stijn.
A guardrail to catch unknown unknowns beyond dbt tests
When the data team first tried a data observability tool, they discovered issues and knew they needed this in their data stack. They considered building anomaly detection capabilities in-house, taking inspiration from their Grafana setup, but quickly realized this would be at least one data engineer’s full-time job.
“Working with data operations is like working for the Secret Service—we’re only in the news when things go wrong.”
“In a recent example, an analytics engineer made a change to a fundamental dbt model and went on holiday. He was unaware of the downstream ramifications of this issue, creating a drop in the number of rows for one of our more important tables. With SYNQ, we knew about this within 30 minutes of it happening, and it was an easy fix”. Despite having more than 2,400 dbt tests, this type of issue could previously have persisted for months, often being only picked up directly by internal stakeholders in dashboards.
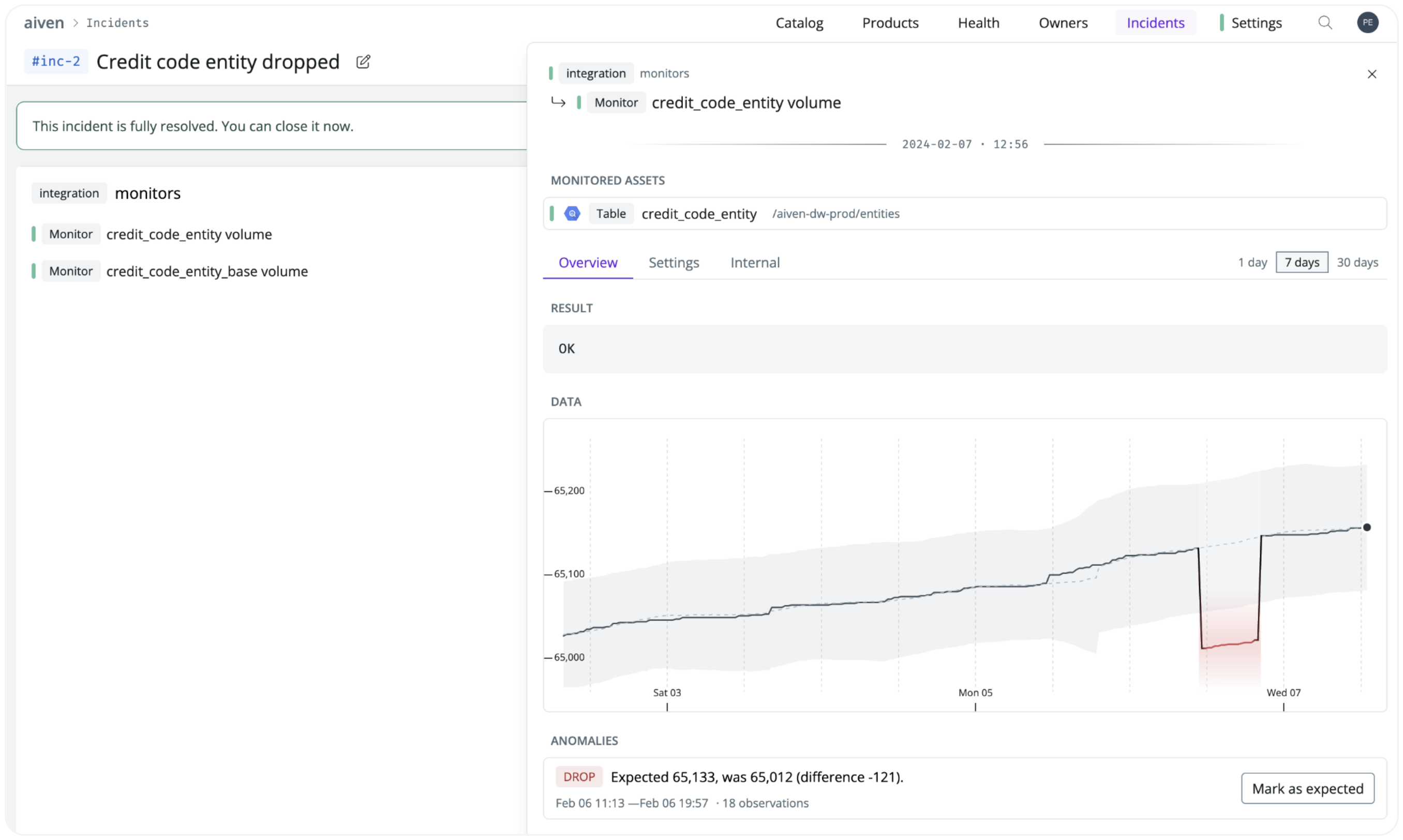
Anomaly monitors in SYNQ offer an additional benefit: they act as an independent layer of insurance across Aiven’s data stack. “In the past, we’d sometimes miss important issues. For example, if everything breaks in Airflow, jobs may not run, and we may not even be notified. We also experienced an outage in Snowplow, causing alerts for event ingests not to be sent. SYNQ runs anomaly monitors every 30 minutes, 24 hours a day, independent of the rest of our stack, and acts as a layer of insurance.”
“A data reliability tool is like an insurance policy. Our leadership team understands the importance of data quality and was immediately bought in on data observability being part of our data stack.”
Data products tightly coupled with dbt
“We’re all-in on dbt. This means we’re always looking for ways to use the latest features, such as data contracts and groups,” says Stijn. A key goal for the data engineering team is getting analysts to fix issues as soon as they pop up. As dbt failing tests block runs, they can’t be left failing for long. “To address this, we want to have different models for analysts so it’s more divided, potentially through multiple dbt projects. A big part of why we moved to SYNQ is that they have the platform most invested in dbt, and we can count on them to invest in and build support for new functionality.”
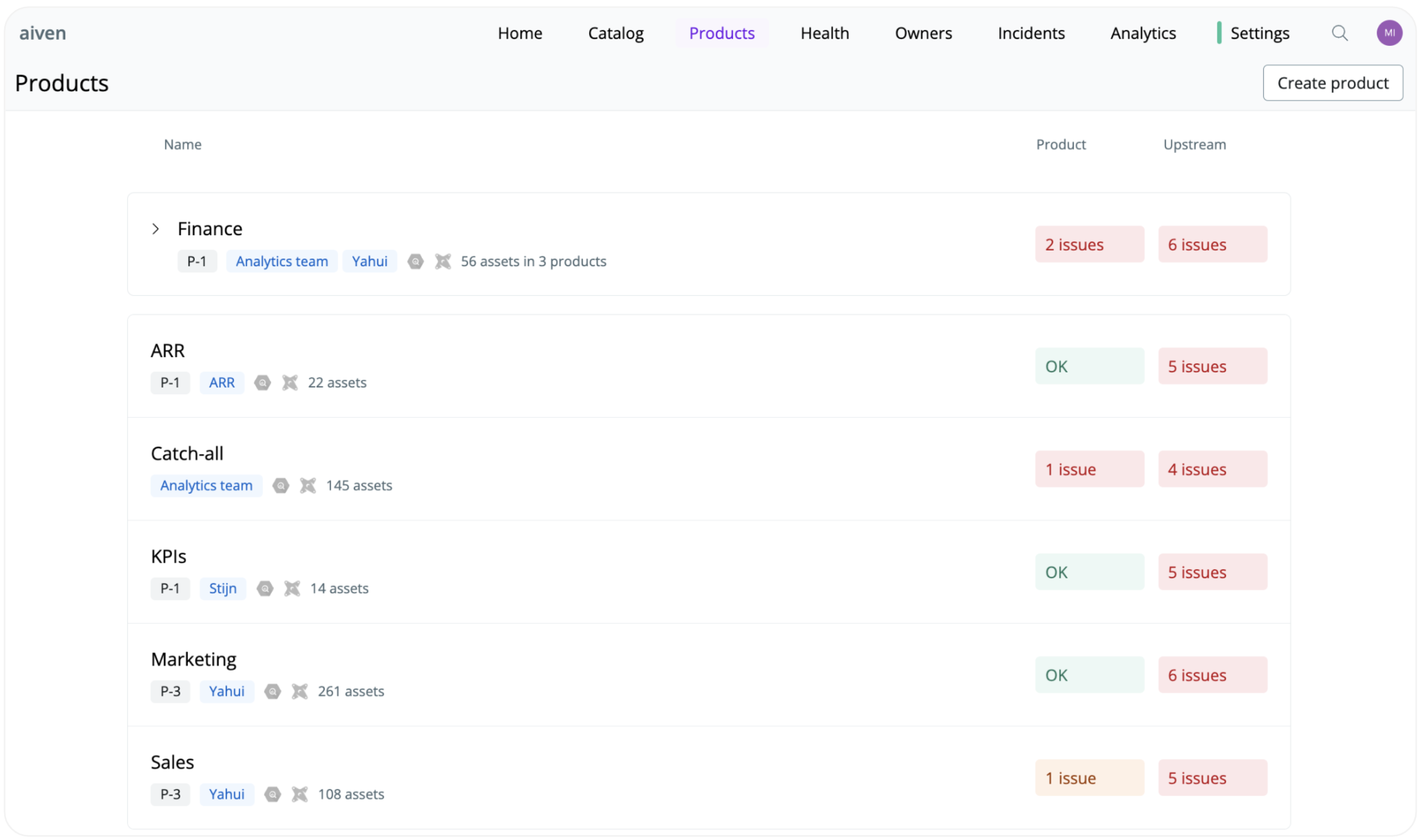
As part of delivering reliable data to the organization, the team built data products to encapsulate the business’s deliverables, such as sales, marketing, and ARR. “In SYNQ, owners of data products can immediately see if there are any issues on the data products or upstream of it and if any ongoing incidents impact the data product. This gives everyone a pane of glass into the uptime of data that can be communicated to the business,” says Stijn.
The team got some learnings about what makes useful data products. They started with high-level products such as Sales and Marketing but realized they needed to go a step deeper to have the most impact. For example, if the Marketing data product has an issue, that may be fine. However, if the Attribution data product within Marketing has an issue, they must immediately jump on it. This is the level of detail the data products need to be able to capture going forward.
Creating a culture of treating issues and incidents differently
The data team thinks about incidents as something that must be fixed immediately. On the other hand, issues may indicate something wrong but don’t require immediate attention. “Before SYNQ, we didn’t declare incidents in the data team, which could create an overwhelming feeling that important issues would get lost in the noise. Now we’re more organized. Important issues are declared as incidents and closed when the root cause has been fixed. We can see downstream impacted products and owners, and the activity log highlights who’s working on what.”
“Admittedly, we still have a long way to go. Our team still mostly relies on Slack, and we reach out to other areas of the business ad hoc and not through declared incidents. But we’ve made the first step in a cultural change to take data more seriously, and it ties well into the overarching framework we’ve built around unified monitoring and data products for the most important data,” says Stijn.
“We’re on incident #86. One benefit is that we can look back at any given month and get a complete overview of all declared incidents. This gives us visibility into problematic areas and the ability to address systemic issues.”
“SYNQ is the right fit for us from a feature and functionality perspective. But they are also the right partner for us at their current stage. We have weekly check-in meetings with the team and are close to the product and data experts. If we have issues, such as nested fields in BigQuery not showing up in the column-level lineage, they will fix them, often within a few days. They also listen to us, and our feedback meaningfully impacts the direction of the platform.”
“Our previous data reliability provider was focused on integrating with as many tools and being as configurable as possible. A side effect of this was that it became really hard to use. We didn’t use 90% of the features and always questioned if we had the best setup. SYNQ is opinionated by default and pushes us into best practices.”
Build with data you can depend on
Join the data teams delivering business-critical impact with SYNQ.