Building our SQLMesh Integration

Data Observability for SQLMesh
We recently launched our integration with SQLMesh (if you’ve missed it, read the announcement on SQLMesh’s website). From day one, we’ve been big believers that a model-centric approach to data modeling is the way forward. Therefore, we started by building the market-leading dbt integration and have now expanded to SQLMesh as the first data observability tool.
Below, we’ll dig into technical considerations when integrating with key concepts in SQLMesh such as virtual data environments, model properties, and metadata.
SQLMesh’s virtual data environment
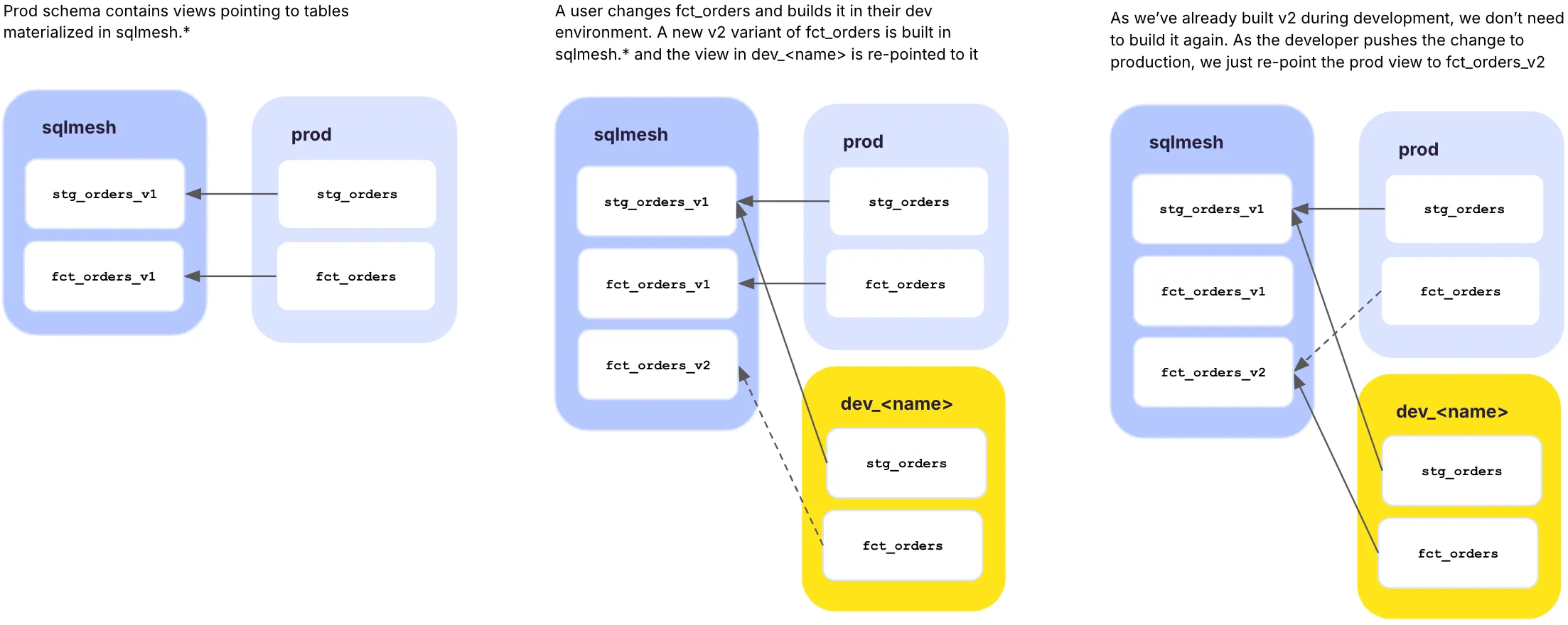
SQLMesh’s virtual data environment is a novel approach to DataOps that provides low-cost, efficient, scalable, and safe data environments that are easy to use and manage. Instead of duplicating massive datasets, SQLMesh creates views that reference materialized tables. This means you can spin up dev, staging, and test environments instantly—without the storage overhead of duplicating tables.
When you start developing, SQLMesh creates a dev schema that mirrors production but keeps references to stored data. This avoids re-materializing upstream tables, as only new tables are materialized.
Each version is stored in the storage schema as you iterate on a model. Deploying a change simply updates the production schema’s views to point to the latest version, while old versions remain available for rollbacks until cleanup.
Every time a model changes, a snapshot is created to capture the change. Each snapshot represents the state of a model at the time the snapshot was generated. In SQLMesh, snapshots are generated automatically when a new plan is created and applied. – SQLMesh’s website
SQLMesh virtual data environment in action – save cost and time in your development work
Mapping virtual tables to actual tables in SYNQ
One challenge with virtual data environments when deploying anomaly monitors in SYNQ is that as developers apply changes to models, they end up with many tables, each stored as a different hashed version. Enabling monitoring on all tables makes little sense–after a new environment table is promoted to production, it stops receiving updates, which would incorrectly trigger the freshness monitor. At the same time, manually updating monitors to point to physical tables used in production is infeasible for any constantly changing real-world project.
At SYNQ, we’ve built a resolution engine to model and navigate complex data relationships. This lets us express advanced relationship concepts through an intuitive query Domain-Specific Language (DSL), making it easy to extract key insights.
For example, we can easily ask:
- “Given that this table is managed by an SQLMesh model, find the corresponding Git files storing its logic and retrieve their most recent commits.”
- “Starting with a specific tag, identify all tagged tables, trace them through the SQLMesh layer, and discover the most upstream sources.”
To support the SQLMesh integration, we’ve extended our engine to map models to environments and their snapshots, ensuring they align with SQLMesh’s approach. When monitors are deployed on a SQLMesh model, we translate that model through environments and snapshots to the physical location of its data. Then we build a consistent view of model metrics based on individual table metrics changing in time.
SYNQ’s model of resolution of metrics for a model that points to a different physical table during its lifecycle

This means that users can rely on SQLMesh models and snapshots when deploying SYNQ monitors without considering the implementation details of mapping physical and virtual data environments.
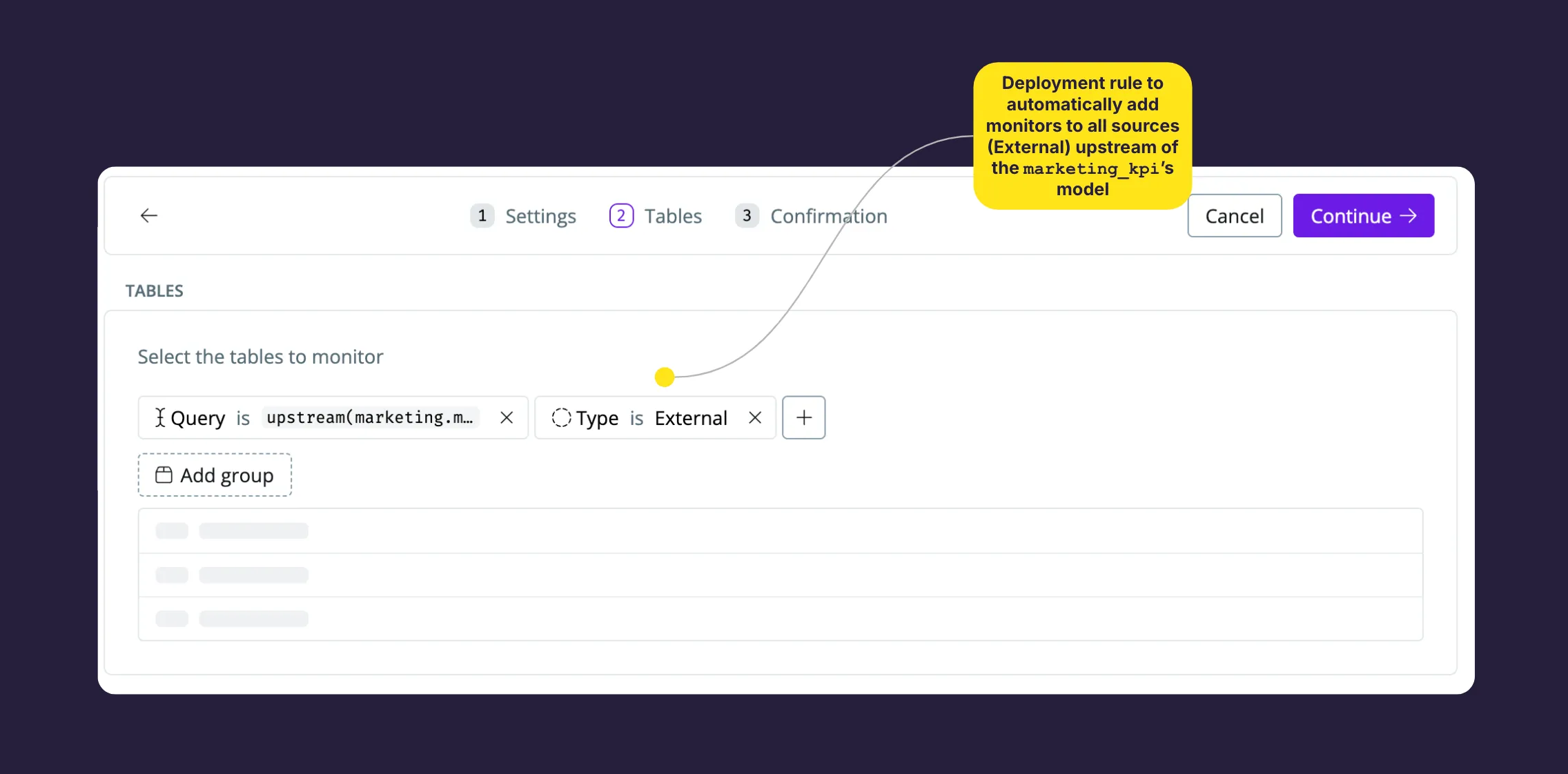
Why should you care about this as a data practitioner? With this at hand, you can use SYNQ’s engine to automatically deploy monitors based on SQLMesh asset types. In the example below, we automatically deploy the relevant row count and freshness monitors on the upmost sources (Type: External) from the marketing_kpi’s SQL model – a handy way to keep monitoring intact as you add new sources.
Making use of metadata and model properties
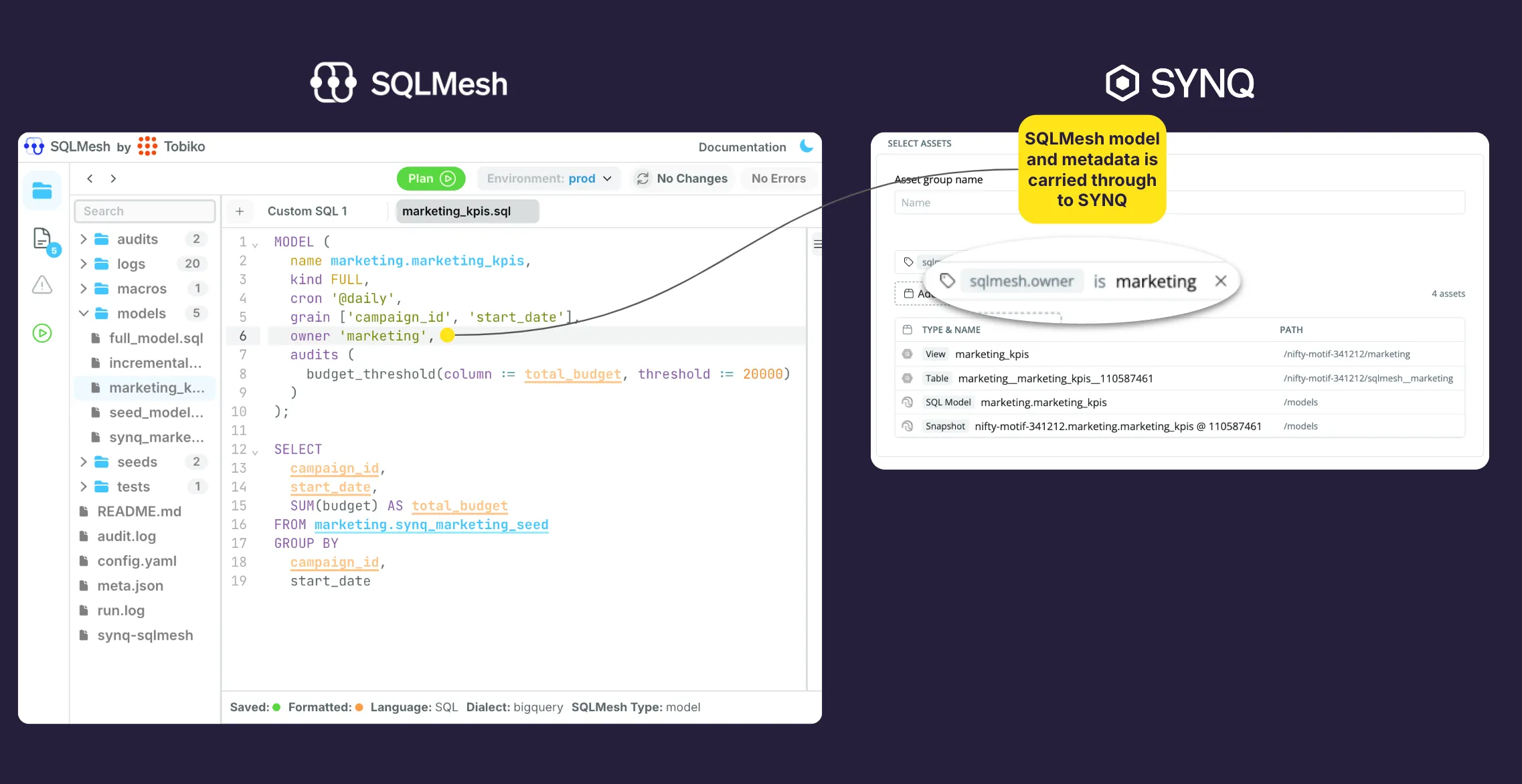
Another key part of our integration engine is that we parse all model properties and Metadata from SQLMesh directly into SYNQ. This lets you keep your DataOps workflow in SQLMesh and use all the benefits that come with defining things in code, such as version control, in SYNQ.
Model properties from SQLMesh are carried through to SYNQ
You can use this across key workflows such as:
- Data products – Define your most important data use cases in SQLMesh as data products in SYNQ by carrying over the model structure definitions and metadata.
- Ownership & severity – Use SQLMesh model properties, such as owner or tags, to bring ownership into SYNQ. Route test or audit issues alongside other data issues and avoid dispersed alerting workflows.
- Deploying monitors – Use metadata definitions to control what assets to deploy anomaly monitors on.
- Measuring quality – Segment your data quality insights across key tags and model properties to improve data quality metrics and drive accountability.
”People who write the business logic are usually also the ones who need to maintain the code. Having the deployment of code, metadata, and DataOps triggers in one place makes it easier to interact with other tools” - Toby, Tobiko’s SQLMesh co-founder and CTO
Want to learn more about how SYNQ works with SQLMesh? Watch the fireside chat with SYNQ CEO, Petr and SQLMesh co-founder, Toby


