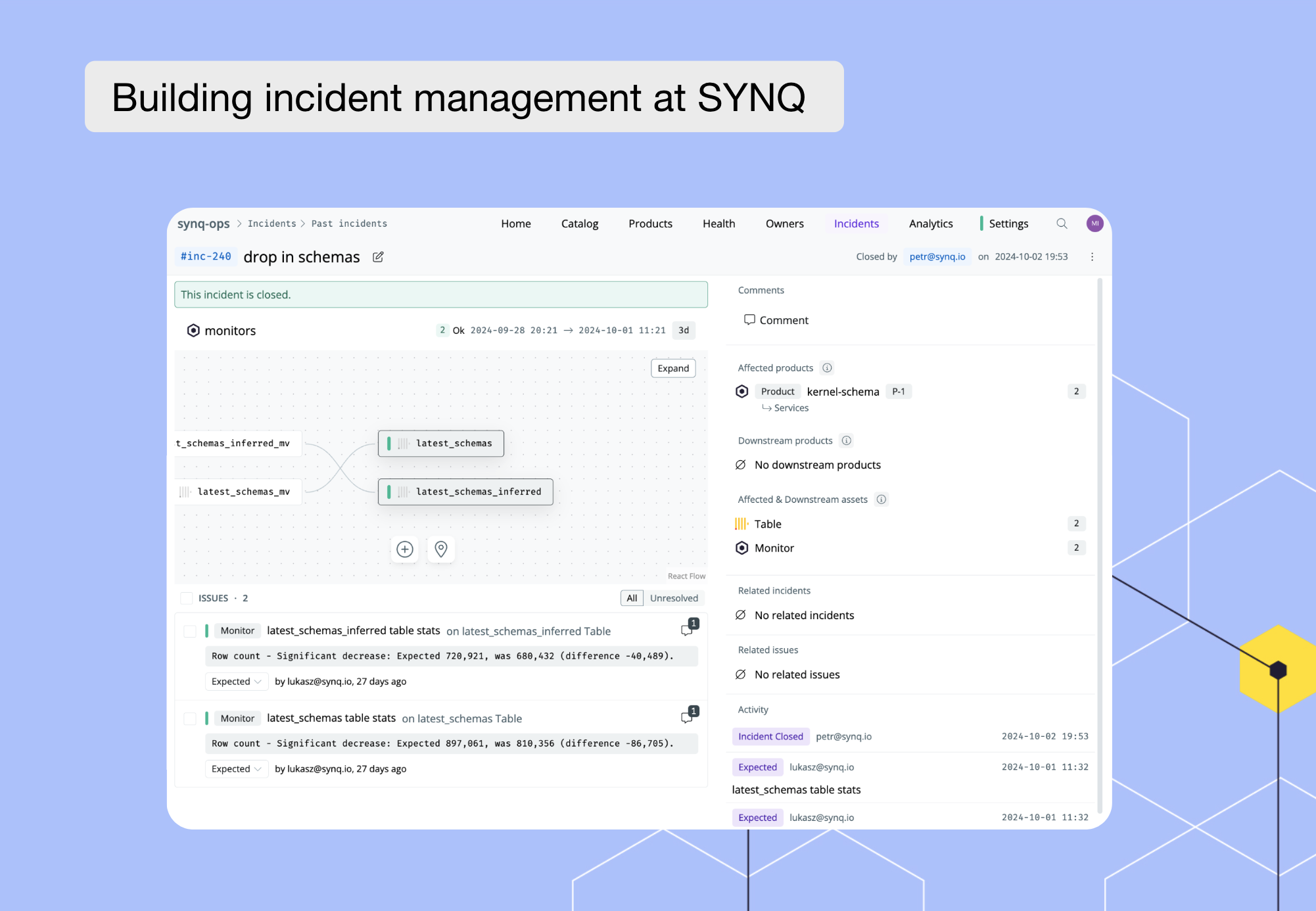
Building Incident Management at SYNQ

Yet Another Incident Management Tool?
The “Why” behind building Incident Management
The “why?” is the cornerstone to building anything at SYNQ. If you understand the why of it, you build something that your customers actually need rather than blindly copy things that are available in the market. The “why” of incident management was multifold. SYNQ was being used by data practitioners across several teams to gain visibility into their data stack, alert them about errors, and allow them to quickly zoom in on the source to find possible causes and measure impact. Our data products, relatively new then, were being adopted to tie together the concepts of ownership, impact, and visibility. What was lacking was a way to give these detected errors a lifecycle that was in line with the teams’ processes.
Why not integrate
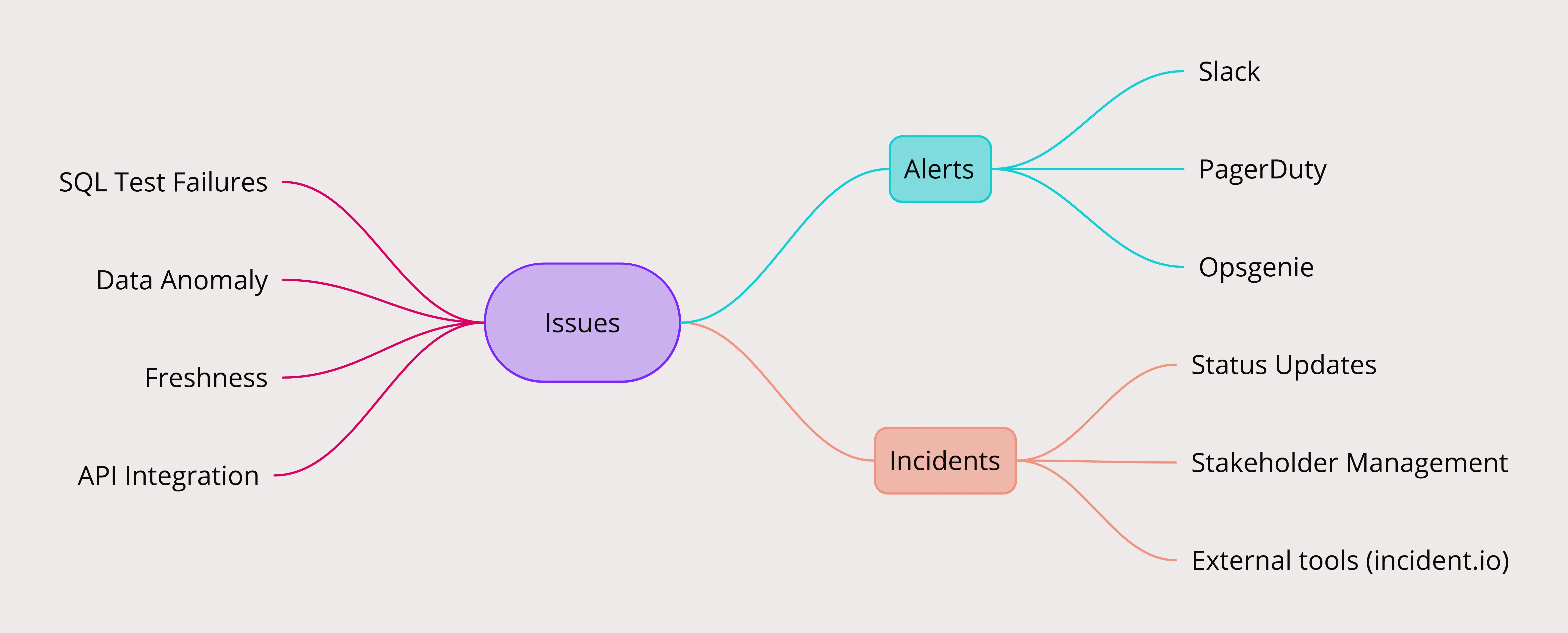
While Incident Management is an established workflow within product engineering, it sees a lower adoption in the data world. One reason we observed was that the experience of most of the existing tools is not tailored for data teams. These teams typically have to deal with a vast multitude of systems with data flowing from one extremity to the other. A useful incident management tool would need to tie all of the moving parts together, and that is exactly what SYNQ’s value proposition was.
Despite the plenitude of good tools available, we figured that it would be a flaky patchwork at best to simply integrate without having the basic concepts within SYNQ. We understood very well that this was a vast product area of its own, so we did not want to jump into the rabbit hole of building all of it. Just enough to control the user experience and open enough to integrate with any tool out there and provide a unified experience with SYNQ’s in-house alerting.
These decisions would validate themselves when we saw our customers use the tool as a standalone or with external alerting integrations like PagerDuty and Opsgenie. SYNQ is helping data teams to tame the wilderness of sprawling data warehouses. Here is a case study on how Aiven uses SYNQ to enhance the reliability of their data products.
Identifying key personas
There were multiple audiences for the system we had in mind.
- The data engineer: This user would be typically interested in learning what broke, where in the data pipeline existed, what its impact was, who owned it, and how critical this failure was. If this information was provided to them in a single context it would help them prioritise, debug, and fix the problem. Alert fatigue is one of the biggest fatigue for an engineer and overloading them with unnecessary information typically tends to make the tool a source of white noise that quickly becomes irrelevant.
- The lead: This user usually has a focus area of a domain that they are trying to maintain. They need visibility over the infra that composes their domain and maps its position on the org’s map. Anything failing within the domain is something they would like to know, along with the context to help prioritise and assign it. Plus, they would like to know how these issues proceed and what their current status is.
- Everyone else: Anyone looking at this from a further bird’s-eye view is usually less interested in individual issues and more in the rolled-up numbers. They typically want to know about ongoing failures on the most critical stuff, the time it takes to resolve the failures, how frequently they happen, etc.
Most of us here at SYNQ have faced these problems as one or more audience profiles. The initial discussions were animated and insightful. What works? What doesn’t? What would not scale beyond a role?
We already had several features at SYNQ that were partially solving the above mentioned problems. What we needed now was something that brought all this together into a seamless workflow.
Building Incident Management
Iteration #1: The Basics
The first step was to evolve our existing error detection and wrap it up in the concept of an Issue. Errors were an occurrence in time. Issues existed linearly on the timeline: created, updated, and eventually closed when the system detected the data entity healthy again. Each Issue tracked errors on a single data entity integrated into SYNQ (for example: a dbt model or a ClickHouse table). As a result, we also gained a neat historical view into the health of a single data entity.
Another crucial concept was that of grouping. An Issue Group was a bunch of Issues detected simultaneously. Imagine a single dbt run failing due to a connectivity issue in the middle of the night. Hundreds of tests fail. No one wants a hundred issues raised and alerts sent. Groups kept together Issues detected from a single run and formed the basis for alerting. We rewired our alerting system to work on the detection of these groups and raise relevant alerts without duplication. Data Products helped maintain ownership and reduce alert fatigue even more by tagging the correct individual or group on these alerts.
Issues happen for a variety of reasons only a part of which deserves the immediate attention of a data engineer. Incident was a manifestation of the basic concept that not all issues are equally severe. It is important to distinguish between these two.
The data team thinks about incidents as something that must be fixed immediately. On the other hand, issues may indicate something wrong but don’t require immediate attention.
…
Before SYNQ, we didn’t declare incidents in the data team, which could create an overwhelming feeling that important issues would get lost in the noise.
- Aiven
At any given time, there can be several issues in a data ecosystem but, hopefully, only a few incidents.
Incidents helped highlight that which was severe and track its lifecycle. Activities and comments on individual issues within the incident were tracked to give a historical timeline of how the incident had progressed. Teams could communicate progress either by leaving comments, setting the statuses of issues, or a combination of the two.
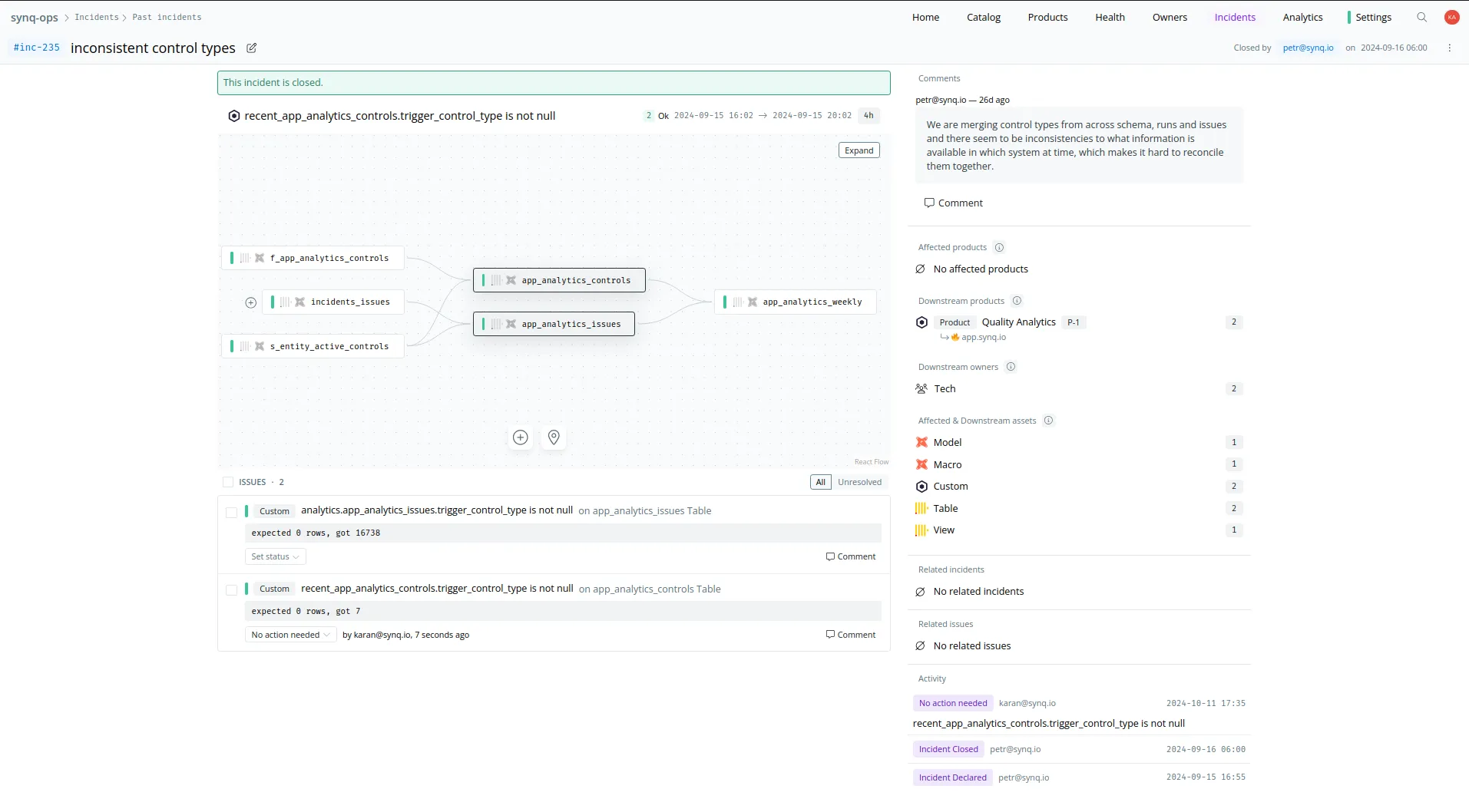
We put these three concepts into a product feature, highlighting new Issue Groups that needed to be triaged and allowing users to systematically work their way through the backlog. We brought the relevant information and workflows into the alerts thus reducing the overhead involved with basic operations like setting status.
These three new concepts also started fueling our, then-nascent, analytics engine. There were interesting rollups that provided insight into the overall system performance. We were deriving more value from the new feature than we had previously gone to board with.
Iteration #2: Letting the User Decide
Once we had these basics in place and integrated well with the rest of SYNQ, we were in a position to focus on the next bit.
Opinionated products are wonderful. They lower your time to be productive and the better ones make some good default choices for you. But it’s a mess when these products put you in a straitjacket. Once you are invested enough, you learn that you cannot do X because the product does not let you. You need to learn to live with the product’s opinion or come up with a complicated workaround which begs the question of whether the integration was worth it.
We realised that our assumption of basing most operations like Incident declaration or dismissal on Issue Groups was inhibiting in various cases. Most importantly, it did not let you declare incidents from issues across different groups. Two related issues could rise from different sources, one from an airflow task and another from a dbt run. Not letting users combine them together seemed like something we would have hated ourselves. We were also discovering that some of our assumptions about Issue Groups were not valid for real-world scenarios. Some of our customers had a single trigger for their data jobs. A failure on these tasks created mammoth Issue Groups which never closed. At any given time, one or more entities within the group was likely to be in error.
Rather than fit the hand to the glove, we made sure that we addressed this problem in a more sensible manner. With the restructuring that ensued, we enabled the following key changes:
- Allowing users to pick and choose issues within an incident.
- Enabling merging of one incident into another.
- Limiting the lifespan of Issue Groups.
- Highlighting new failures in triage.

Now we had the core concepts of our Incident Management tool reworked with validation from multiple real-world scenarios.
Iteration #3: Enabling Workflows
The primary raison d’etre for any Incident Management tool is to enable workflows. We allowed our users to have some basic workflows related to Issues and Incidents but we wanted to take it further.
The first part was to map our incident management concepts to external alerting engines like PagerDuty and Opsgenie. With the alerting abstractions in place, it was a super quick iteration on both these engines. We even managed to pull comments from one of the third-party engines into our system thereby allowing end-to-end visibility. This assured us that we could quickly support any framework that our customers might need. Integrations were not a problem and we were in a position to fit in with the existing workflows of our customers rather than have them choose.
The second revolved around Issue Statuses. These were originally designed for users to communicate the status of the issues to each other. However, we noticed that they were also using it as feedback for the system. At times we received questions about why an Issue marked with No Action Needed was still available for triage. Or why Fixed did not turn the data entity green?
This was especially tricky since we did not want to mix the two things together. The system’s knowledge should not be altered by the user’s actions. An issue should not close simply because a user marked it as Fixed. The next run should confirm it. But there was nothing stopping us from layering the user’s actions on top of the system’s knowledge. The two together would resolve into a data entity’s health.
The key concept here was that of a Resolved Issue. It’s an issue that is not yet closed but is marked with one of the resolved statuses. But we could also imagine each team having their own version of what was a resolved status and what wasn’t. So we exposed it as a setting for the users to choose.
A key indicator of any good design is its simplicity.
This iteration made the concepts of our Incident management tool simpler to understand and work with while providing more flexibility. The other key benefits were:
- Allowing users to work with Issue Statuses of their choice.
- Lowering noise from the triage page and only retaining what was relevant for users.
- More accurate Data Product health stats.

What’s next?
We are far from being done. We have a bucket-load of ideas on how we can take our incident tooling to the next level.
- Intelligent grouping of issues across data warehouses
- Flagging regressions and flaky issues
- Allowing manual issue creation
- Exposing the concepts of incident management through our Developer API
- Integrating with more industry-standard Incident Management and Alerting tools
- RCA workflows within incidents
- Status updates for active incidents
Get in touch or keep following us for further interesting developments.
Want to learn more? Check out these articles
Learnings from running hundreds of data incidents at SYNQ
Why incidents – not issues – must be the basis of data reliability SLAs
Unpacking Synq’s approach to incident management for data teams


