
SYNQ’s 2024 Highlights
Reflecting on 2024, SYNQ introduced the Data Product Observability Workflow, enhancing data reliability through strategic testing, ownership activation, and quality metrics. Key developments include the launch of Data Products for streamlined monitoring and SLA tracking, advanced incident management features, and comprehensive data quality analytics. These innovations have empowered enterprises like IAG and Aiven to optimize their data operations effectively.
Many data teams have shifted their thinking about data observability from ‘interesting’ to now being on their roadmap as a core part of the data governance strategy. There are good reasons for this – data use cases are getting more critical, data stacks and teams are getting larger and expectations are increasing.
Still, too often we see data teams place tests sporadically, with little consideration for the use case of the data, and unclear ownership, creating ‘broken windows’—tests that remain failing for too long. As a result, data teams become overwhelmed by alerts, stakeholders are often the first to uncover issues, and confidence in the value of testing begins to erode.
Most of what we shipped in 2024 focused on addressing this through an opinionated 5-step framework built into the SYNQ platform – from defining data use cases as products, setting ownership & severity, deploying strategic tests & monitors, and establishing quality metrics.
We call it the Data Product Observability Workflow.
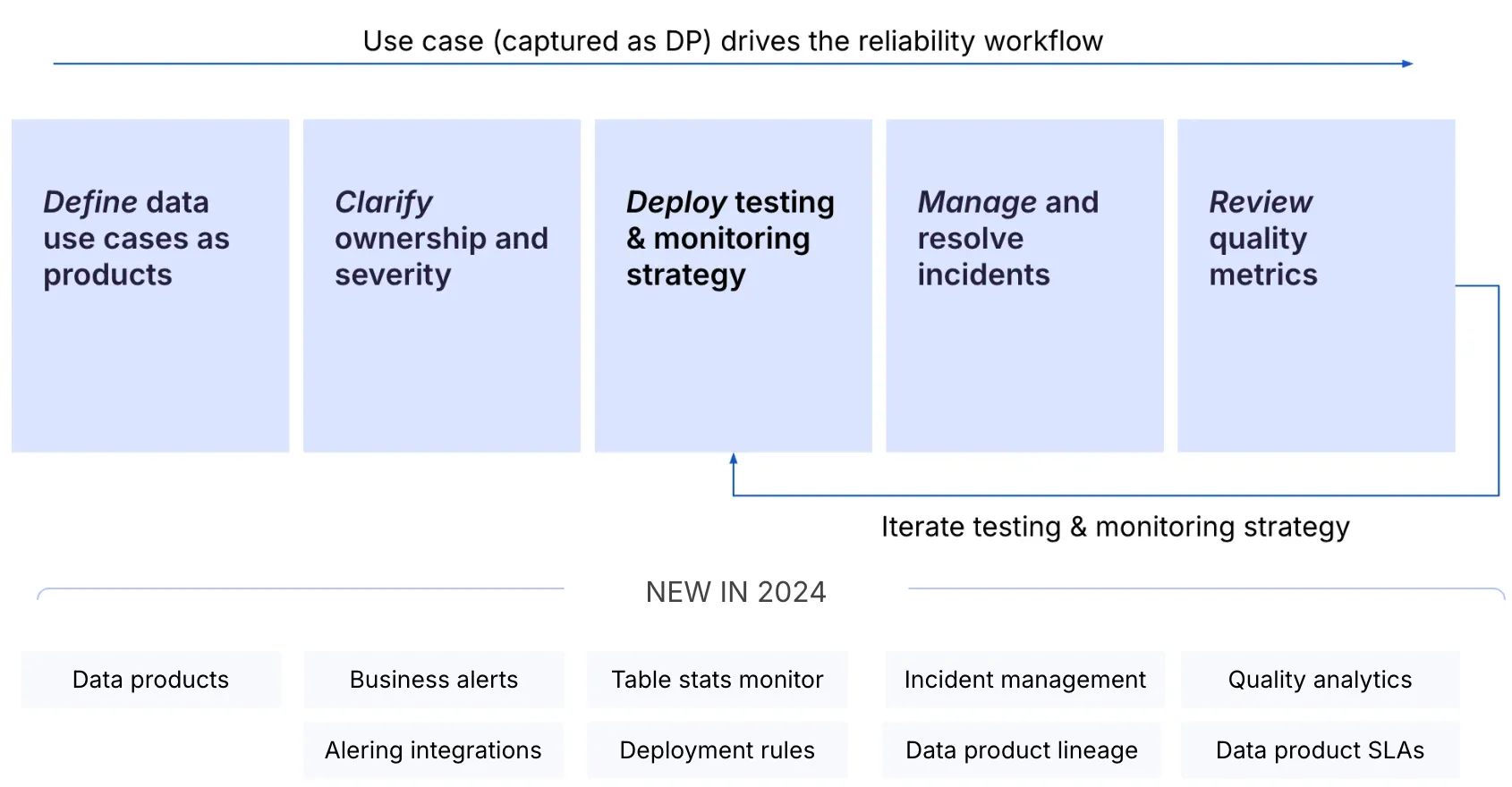
Watch Petr’s talk from dbt’s Coalesce: A strategic approach to testing monitoring with Data Products, for the full story of how we apply the the Data Product Observability Workflow principles at SYNQ.
We invested significantly behind the scenes to support the Data Product Observability Workflow for large enterprises such as IAG, from being able to handle 10,000s of data assets to role-based access management, SOC2, and VPC support.
If you missed out on some of the stuff we shipped throughout 2024, here’s your brief 💼
- Data products: the building blocks for reliable data
- Managing incidents like a software pro
- Improve what matters most with SYNQ data quality analytics
- Bring data ownership outside the data team
- The guide to building reliable data products
See for yourself how it all comes together!

Data Products: the building blocks for reliable data
We shipped Data Products early in 2024 and have made many improvements and iterations with customers to make them fit into core workflows. Data Products have already become a must-have component of building reliable data – from managing the setup of monitors, getting an overview of the health, operationalizing ownership, prioritizing issues, and tracking SLAs.

We’re very happy that our customers have adopted Data Products as a core part of their data reliability workflow. Here are a few examples:
- Aiven uses the data product lineage to improve how they model their data stack
- Ebury uses data products as a pane of glass into the performance of their most important data assets
- Shalion uses data products to distribute ownership to product squads and plans on reporting data product SLA externally to customers
“The Data Product overview in SYNQ is the first page we open each morning to check if all the nightly runs have run successfully or if there are any errors across dbt and SYNQ anomaly monitors impacting our key data products” – Instabee
Want to get started with data products? Read more in the Data Product chapter in our guide
Managing incidents like a software pro
The feedback from data teams was clear – they wanted a way to manage incidents that were on par with what their engineering colleagues had. We worked closely with a handful of design partners to build the best possible incident management experience. Today, you can declare incidents directly from Slack, manage the status, see the downstream impact across platforms, and systemically improve by documenting your incidents making it easier to solve if the issue happens again.

One example of a team that’s bought into incident management is Aiven who has declared more than 100 data incidents since adopting the feature. Read more about how they created a culture of treating issues and incidents differently.
“Before SYNQ, we didn’t declare incidents in the data team, which could create an overwhelming feeling that important issues would get lost in the noise. Now we’re more organized. Important issues are declared as incidents and closed when the root cause has been fixed. We can see downstream impacted products and owners, and the activity log highlights who’s working on what.” – Aiven
You can also integrate with PagerDuty and Opsgenie to send issues directly to systems used across your company to close the loop.
Want to learn more about what went into building this functionality? Read the post from our engineering team: Building Incident Management at SYNQ.
Improve what matters most with SYNQ data quality analytics
To help teams be more systemic about how they think of data quality, we shipped Data Quality Analytics. This lets you track the key performance of your data stack across metrics such as the number of tests, the number of tests with issues, the number of incidents, and new versus resolved issues. Insights can be broken down into segments such as Owner, Data Product, and Platform and monitored over time to drive accountability.

A great example of how this is used is the Danish fintech, Lunar. Lunar meets with the C-level each quarter and brings them up to speed on the performance of the data quality, including gaps and focus areas. This helps bring everyone on the same page and ensures that if regulators ask, they can show that they have strong controls in place. Watch the Lunar story here.
If you want to learn more about how to use analytics, read this chapter in our guide: Continuous improvement.
Bring data ownership outside the data team
We’re big believers that ownership of data shouldn’t stop with the data team. In fact, most issues can be traced back to upstream data sources, such as an engineer making a change that has unintended downstream effects or an input error in an operational system.
There’s no one-fix-all solution to this problem but we’ve shipped a few features we’ve already seen have an impact: Business alerts – customize the message for alerts so that non-technical stakeholders can act on them and BI status tiles – show directly in your BI tool if there are any known issues on or upstream of it.

A great example of how this is used in practice is Ebury. They have created a set of tests to catch issues caused by upstream teams and send “business alerts” from SYNQ that can be understood without any context about the data stack. Read their story here.
Want to learn more about how to operationalize ownership in and outside the data team? Read our chapter: Ownership & Alerting.
The definitive guide to building reliable data products
Building data products is complex. Scaling them to meet business needs is even more challenging. From working and speaking with more than a thousand data teams, we’ve got a good understanding of what challenges they face day-to-day.
We’ve put these learnings into a guide that walks through how you can adopt the Data Product Observability Workflow. No matter if you’re a 5-person data team or a data team in the Fortune 500, we think there’ll be a lot of useful information in there for you.
Check it out: The Definitive Guide to Building Data Products

A must-read book for data professionals building analytical data products that power business-critical applications
One of our core values at SYNQ is ‘experiment and learn fast’. The best way to do this is to be as close as you can to where your customers work.
In 2024, this brought us across the world – from dbt Coalesce in Las Vegas, the Snowflake Summit in San Francisco, Big Data LDN in London, The Data Innovation Summit in Stockholm, The Data Forward Summit in Paris, and dinner and breakfast events in Barcelona, Stockholm, London, Copenhagen, Paris, Berlin, and Tallinn.

Highlights of 2024 – meeting hundreds of customers across the world and getting together for “reSYNQs”
Come on in. The water is warm 🛁
Thanks to all our customers, new and old! Without their feedback, we’d be flying blind.
If any of this sounds interesting to you, we’d love to have a chat. Here are a few ways you can stay in touch
- Follow us on LinkedIn for regular updates
- Check out our data reliability guide
- Book a demo on synq.io
See you in 2025 🥂
The SYNQ team


Build with data you can depend on
Join the data teams delivering business-critical impact with SYNQ.