
Unpacking Synq’s approach to incident management for data teams
Explore Synq’s tailored approach to incident management for data teams, highlighting key stages like issue detection, triage, handling, and post-incident analysis.
One of the most dreaded moments in the life of a software engineer is when the war-room Slack channel lights up with new notifications. It can only mean one thing. We have an incident.
What follows is (or at least should be) a military-precision coordinated collaboration between a squad of on-call engineers and SREs to get the system to a healthy state as soon as possible.
This process is called incident management and, until recently, it ran exclusively in software engineering teams. Data teams didn’t get a look in.
But as data finds its way into core processes and user-facing products, it’s becoming critical for the business. It needs to be reliable. And that means it needs to be incident-managed.
The data teams we talk to every day recognize the need to run incident management. Yet they lack the processes and tools to do it well.
That’s because incident management in data organizations will only work with data-specific tools. Hooking your dbt or monitors straight into pager systems is just too crude. Data teams need more control.
With these newly elevated requirements and expectations in mind, we’re bringing best-in-class practices around incident management into Synq. Our approach is inspired by decades of experience managing incidents as software engineers, but it accounts for the nuances of data teams.
Let’s explore the four key stages of the incident management process, which are issue detection, triaging issues, handling incidents, and post-incident analysis. At the same time, we’ll highlight the specifics of Synq’s approach to each stage.
Stage One: Issue detection and alerting
The origin of an incident is when something goes wrong. An important dbt job fails, a table stops receiving new data, or an SQL test that verifies data integrity fails. At this stage the failure is still just an issue, and the system should deliver on the following three objectives:
- Detect the issue as soon as possible
- Ensure the right person is alerted
- Provide relevant context
Detecting an issue and alerting the right person with relevant context so they can assess what is happening is the first step of system recovery.
The Synq solution to issue detection
Due to our integration with tools such as dbt or Airflow, we have near real-time understanding of the execution status of company data pipelines. By connecting with our anomaly monitors, we can be a central hub for the data team, creating a unified backlog of issue alerts across the entire stack for them to triage.

Stage two: Triaging issues and declaring incidents
With an alert at hand, it’s time to assess what happened. It’s important to remember that an alert does not always contain all the context needed, and a system failure might have occurred in connection with other relevant issues.
At this triage stage all recent issues should be available for inspection with the primary goal of helping the development team answer some fundamental questions:
What is the scope of the failure? Is it isolated, or do several failures relate to each other? What is the impact? Are critical datasets affected? How severe is the failure? Is data unavailable, corrupted, or unreliable?
Together, these questions provide the necessary context to fully assess the issue (or issues) and decide if an incident needs to be declared. This triage step is essential and allows teams to separate severe issues from minor ones that don’t need complete incident treatment.
The Synq solution to triaging issues
The triage workflow in Synq is simple. In case of issues, the relevant team member is alerted, and Synq provides a complete overview of failures with relevant context. This allows data engineers and analysts to assess the severity of issues, as well as how they relate to each other.
We’ve integrated incidents with data products (our functionality to codify business-critical data), which we use to highlight impact. For every issue, all impacted data products are automatically highlighted as part of the triage workflow.

Stage three: Handling the incident
Once an incident is declared, the system should provide the tools necessary to:
Communicate the impact to relevant stakeholders, including owners of affected critical data Coordinate the team and track who is working on what Help to find the root cause of the incident
The heart of the incident management workflow is coordinating the team around fixing the issue, communicating with the rest of the organization, analyzing logs and error messages to identify the root cause, and ultimately restoring the normal function of the data platform.
The Synq solution to incident handling
For declared incidents, we have a single overview of failures. Issues are all related to each other in lineage, which helps identify the underlying failure. This guides the team to address the potential root cause first, rather than spending time diagnosing the consequences.

The team can assign individual issues and update their status – both in Synq and directly from Slack – to keep track of who is working on what.
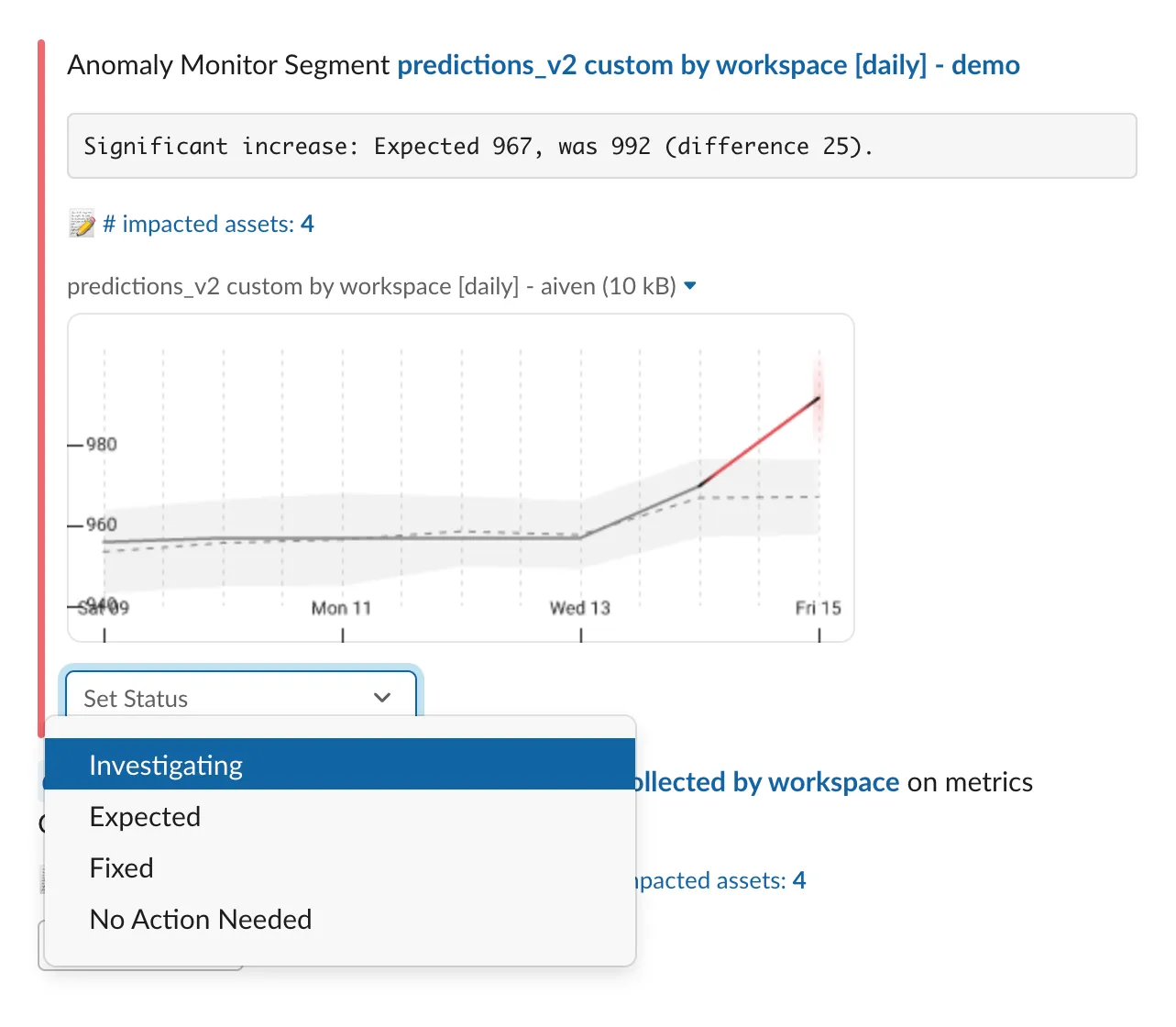
The issue’s impact is always accessible, with relevant details of precisely which data products, tables, dashboards, and teams are affected.
To ensure teams are able to capture context, we’ve introduced lightweight comments in Synq to leave notes about issue resolution. Issue comments are not only relevant throughout the incident itself – because they are attached to the affected asset, they can surface in case of future incidents to indicate how issues were solved in the past.
Synq doesn’t directly facilitate communication with stakeholders. Instead, our solution empowers the data team with the relevant information about who to contact first. We’ve also integrated incident communication into data products. The incidents declared on assets related to a data product or its upstream dependencies are displayed on relevant data products.

Stage four: Post-incident analysis
Finally, once an incident is resolved, the issue, solution, and context must be analyzed.
Mature technology organizations often have an established post-mortem analysis process, where the entire incident is reviewed. Data teams should aspire to adopt this process too, as it’s a valuable source of lessons learned and provides useful feedback for future development.
To enable this post-incident analysis, the incident management process must automatically track the activity and context as the incident is being handled. As well as being a source of information for post-mortem analysis, this provides relevant context that can be surfaced if the incident reoccurs. In addition, rich incident data provides a solid foundation for the calculation of system SLAs, uptime, and overall quality.
The Synq solution to incident analysis
Our approach to explicitly declared incidents is unique across data tools, and it yields an obvious analytical advantage because we can calculate system metrics on two levels. First, we can track internal metrics for the data team at issue level. In engineering this is often called error budgets. Second, we can track at the incident level, allowing calculation of system health, uptime, and SLAs based on declared incidents. Take a look at our recent article to find out more about why data reliability SLAs must be based on incidents, and not issues.
With the above approach, our data product dashboards become status pages of the data platform. We can highlight critical parts of the data platform, their current status, and the history of failures declared and managed by data teams.

Integrations to enhance incident management
As we built incident management into Synq, we faced an important decision. How significant a portion of the above process should we cover in the platform itself versus integrating with other solutions on the market?
Considering this question gave us further clarity on what Synq is not:
We are not a ticket management solution. We are not a company-wide incident management platform.
Instead, we focused on parts of incident management that uniquely benefit from integration with our existing product and alerting solution. We aimed to cover all data-specific parts of the workflow, where tight integration into Synq brings unique value that would be hard to build for more specialized tools. This approach enabled us to create an end-to-end workflow with clear integration points.
We’ve already found great integration opportunities with workflow management tools such as Linear and Jira, and with incident management solutions that are predominantly used across engineering teams, like incident.io, Opsgenie, and PagerDuty.
We are actively exploring these integrations and are always interested to hear from the community on the ones they find most valuable and what the intended workflows would look like.
Improving incident management in 2024
A mature incident management process is essential to ensure data reliability can scale to support the complexity of today’s business-critical systems.
With increased criticality, a well-run incident management process empowers data teams to play a more central role in their companies. Reliable data platforms will underpin the adoption of business-critical data use cases and accelerate the adoption of user-facing data products, AI systems, and business systems automation.
We’re enabling the emerging practice of incident management for data teams and have laid a foundation for our next step – robust data quality analytics. Due to the tight integration of this new concept across alerting, data products, and other parts of Synq, we’re seeing incredible adoption among our customers. We’re being met with great enthusiasm as many data teams set goals around improving incident management practice in 2024.
If you’re one of them, we’d love to help!


Build with data you can depend on
Join the data teams delivering business-critical impact with SYNQ.