







About LendInvest
One of the largest non-bank mortgage lenders in the UK, LendInvest is a leading fintech platform designed to facilitate property lending, especially for non-traditional borrowers poorly served by mainstream banks.
| Industry | Data stack | Company size |
|---|---|---|
| Fintech (mortgage lending) | AWS, dbt Cloud, Synq, Tableau, Metabase | 250+ |
By the numbers:
- Time to identify business-critical data issues reduced from weeks to minutes
- 11x reduction in data runtime; data now runs every 30 minutes, instead of once daily
- Already detected 10s of issues in near real time before they could materialise into a business risk using automated reconciliations between core systems
About the interviewee:

Rupert is leading a team of engineers and BI developers in building a modern data platform
“We now catch issues proactively— the relevant teams outside of the data team are responsible for fixing breaking changes caused by data from systems they own. This frees up the data team and reduces the time to resolution.” - Rupert Arup, Data Team Lead
The aim: Improve data accuracy, reduce reconciliation errors, speed anomaly detection, and notify stakeholders.
The challenge: Manual data reconciliation created inconsistencies. Slow batch processing of data limited visibility. Centralized model testing blocked other work. Root causes of data failures and mis-matches were difficult to track down.
Connecting Unconventional Mortgage Borrowers and Lenders
Founded in London in 2008, LendInvest is a fintech firm that acts as one of the largest non-bank mortgage lenders in the UK. It provides service lending by positioning itself between large institutional lenders and individual borrowers who—for a variety of reasons— may not meet mainstream lending criteria.
As Rupert Arup, LendInvest’s Data Team Lead explained: “Our focus used to be on buy-to-let and specialist lending, but we’ve just entered the residential mortgages market. With that business expansion comes a lot more pressures, more regulated reporting and the need for more testing.”
LendInvest handles the full lending journey—from underwriting through origination. Their platform is designed to equip underwriters with the data and customer insights needed to make informed decisions. This information is vital when clients are dealing with unconventional borrowers.
”Our primary customers are brokers,” explained Rupert “The market is intermediated in the UK, so you don’t really have customers directly choosing who they’re going to get their financing from. Therefore, a lot of our work is around creating that relationship with those brokers. Being able to present them with clear, concise, accurate information is vital to providing a good customer experience.”
Legacy Systems Creating Major Data Risks
Supplying the brokers with the data they needed, however, has not always been easy. Until a few years ago, LendInvest relied on a legacy MySQL data warehouse, Python, and SQL scripts to handle its data needs. While the setup had been sufficient when the business was smaller, the system had several systemic issues that grew as the years passed.
Perhaps the most risky of these issues was that the legacy system struggled to handle the thousands of data models and dashboards LendInvest needed to meet the demands of its customer base. The team struggled with testing and troubleshooting, making it hard to surface and reconcile data mismatches.
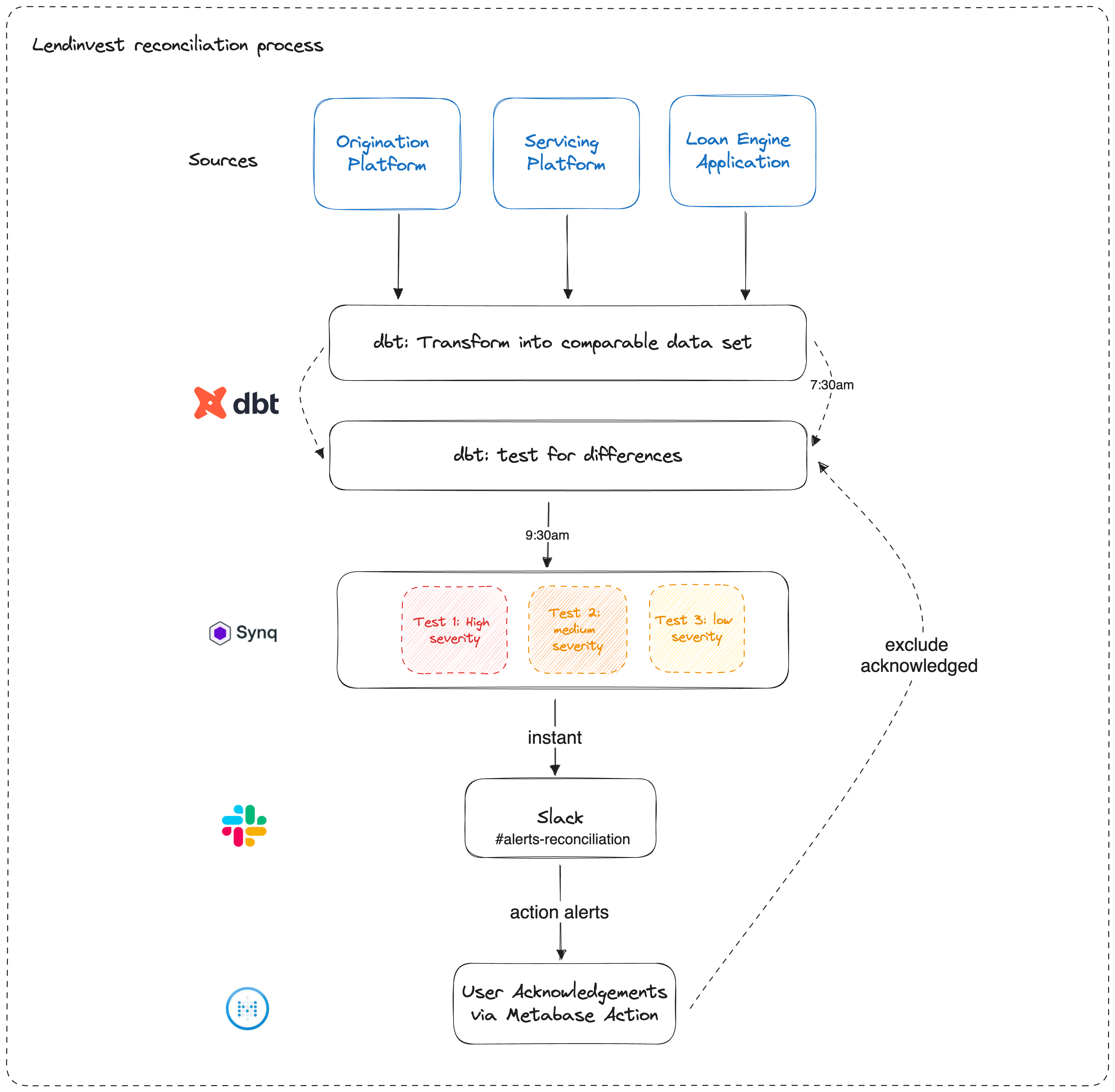
”We bring in data from three different systems—our origination platform, servicing platform, and internal loan engine,” said Rupert. “If we write a loan, we expect the same loan amount, interest rate, reversion rate, etc., on the offer letter to match up with all of the systems.
However, we were finding small errors where someone changed data in one place, and it hadn’t synced through to other systems, or they retrospectively changed the data after we had already produced reports or offers.”
For a business operating in the heavily regulated financial services sector, this kind of mismatch can be much more than a mere annoyance. Making errors on loan offers and failing to provide pristinely audited data pose serious issues, and even relatively small mistakes can result in severe reputational and regulatory consequences.
”If we end up submitting something incorrectly to the Financial Conduct Authority (FCA), we can get fined,” Rupert explained. “If you get it wrong, and you find out later, there’s a real risk that you incur a huge charge. If you keep making errors for a sustained period of time, you could be fined by the FCA or regulated out of existence.”
An Opaque Legacy System
At the same time, the tooling barriers to easily surface information made data lineage tracking difficult, hampering the team’s ability to reproduce and debug failures.
”We were unable to recreate the past,” Rupert explained. “Whenever we wanted to run something end to end, we had to know the order that things ran in, but our legacy stack just couldn’t do that reliably. Things became unscalable.”
Without clear data lineage and reproducibility, the team struggled to resolve bugs or inaccurate data buried in the pipeline. The lack of clarity of the legacy orchestration scripts made troubleshooting difficult and prevented innovation. The team spent most of its time “just making things run” rather than delivering new value.
Processing speed degraded over time and the team was investing all their time into just meeting service level agreements (SLAs) for timely data delivery.
Failure to meet SLAs, together with frequent complaints about stale or incorrect data from business users, provided the impetus to upgrade to a modern cloud-based data stack.
Automating Data Reconciliation with dbt Cloud and Synq
To address their data consistency challenges, LendInvest implemented a powerful solution leveraging dbt Cloud and Synq, a data reliability platform.
First, the data team built dbt models to extract and transform loan data from the organization’s three core systems before normalizing it into comparable formats. Custom dbt assertion tests then check for discrepancies across the systems, such as differences in loan amount, interest rate, or other key fields.
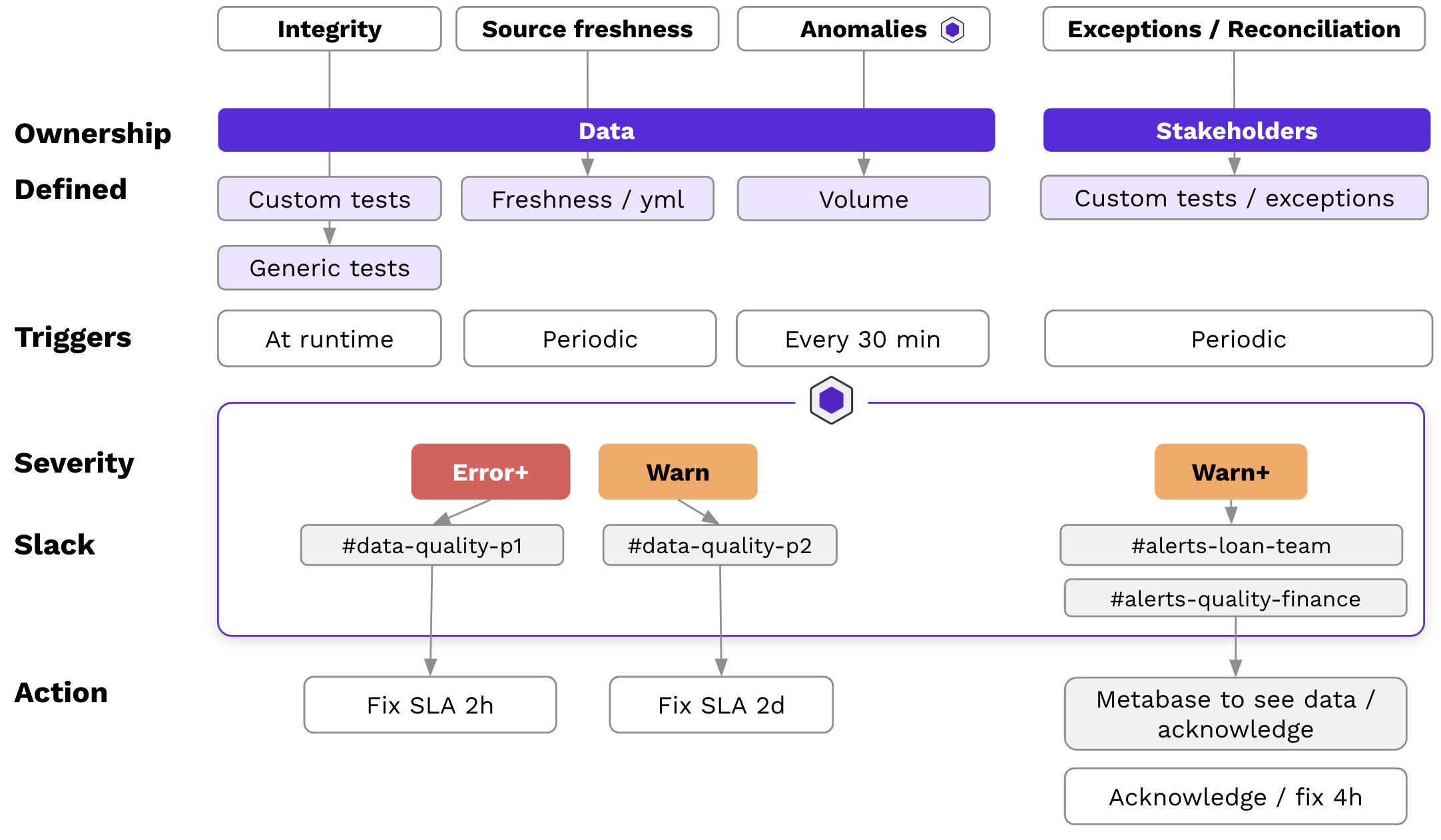
These tests validate any new loans against the downstream data models in near real-time. When discrepancies are detected, Synq automatically routes alerts to the responsible teams based on severity. For example, a high-severity alert is sent immediately to a senior stakeholder who can escalate if needed. Lower-priority issues are routed to operational staff.
This development process creates a scalable workflow and audit trail. Alert recipients can dig into the specific data differences in Metabase and mark issues as acknowledged, fixed, or acceptable one-off differences.
”We get these alerts on an hourly basis rather than a quarterly basis,” said Rupert. It means that we can alert on different levels. We have integrity alerts, source freshness alerts, exception alerting, and more recently we’ve been adding anomaly alerting.”
This automated, rapid reconciliation between core systems ensures data accuracy and prevents regulatory mishaps or negative customer experiences.
Rapid Debugging Frees Up Valuable Time
Previously, the data team had to dig into the data, find issues, then track down who was accountable. This consumed hours of data team time.
With Synq and dbt Cloud, debugging accelerated as the team can reuse and run SQL scripts against the database within 10 minutes rather than an hour to isolate the problem: “It speeds up everything by at least 100%,” Rupert emphasized.
By setting granular alert routing based on severity and groups of models failing, resolution times are also faster. This means the data team spends more time innovating versus wrangling tedious debugging.
Whereas previously data was processed in 12-hour intervals, the team can now provide near real-time processing. This gives the entire business—and the brokers it works with—confidence the data is accurate.
Next Steps: Expanding Tests to Cover More Use Cases
Looking ahead, LendInvest has plans to continue expanding its use of automated testing and reconciliation powered by dbt Cloud and Synq.
One priority is implementing more anomaly detection tests to uncover unusual spikes, dips, or other unexpected patterns in the data. This will provide another layer of monitoring to catch potential issues early.
The team recently took the first steps by monitoring their 50 most important tables with Synq volume monitor checks that look at table row count. It’s important for the team to catch issues in near-real time so the checks run every 30 minutes.
“Last week, we were notified of a sudden drop in the number of rows in our postcodes table we may otherwise have missed. This was caused by a change in the categorization that the Office for National Statistics uses, which would have gone unnoticed otherwise, potentially exposing us to missing postcodes in our database. As a property business, this is critical data, and Synq helped us detect this, rectify the problem, and mitigate any future risks”
LendInvest also aims to involve more business analysts outside the core data team in the dbt development process. By giving analysts self-service access to curated dbt models, their domain expertise can be leveraged to build even more insightful tests tailored to their specific business needs.
”Moving to a less centralized data team model will be key over the next six months. We’re looking to see how we can scale the insights we’re getting out of our platform without scaling our team”
Ongoing investment in testing coverage will reduce reconciliation errors and improve data accuracy across the board. The ultimate goal is continuous validation so customers—whether borrowers, brokers, or auditors—always see pristine, trustworthy data.