ML & Gen AI for data teams

AI and ML are at the top of most data teams’ minds, and rightfully so. Companies are achieving real impact from AI, and data teams are sitting right in the middle of this, giving them a much-desired way of tying their work to ROI.
In a recent example, AI helped automate 700 full-time agents for the Swedish ‘buy now, pay later’ fintech Klarna. Intercom is now an AI-first customer service platform, and executives have OKRs directly tied to implementing Gen AI use cases.
“The AI assistant has had 2.3 million conversations, two-thirds of Klarna’s customer service chats. It is doing the equivalent work of 700 full-time agents. It is on par with human agents in regard to customer satisfaction scores. It is more accurate in errand resolution, leading to a 25% drop in repeat inquiries” – Klarna
In this post, we’ll look into what this means if you work in a data team.
- State of AI in data teams – how data practitioners use and expect to use ML and AI
- AI and ML use cases – the most popular ways data teams can apply different types of models
- Data quality in AI and ML systems – common data quality issues and how to spot them
- The five steps to reliable data – how to build AI and ML systems that are fit for purpose for business-critical use cases
State of AI in Data Teams
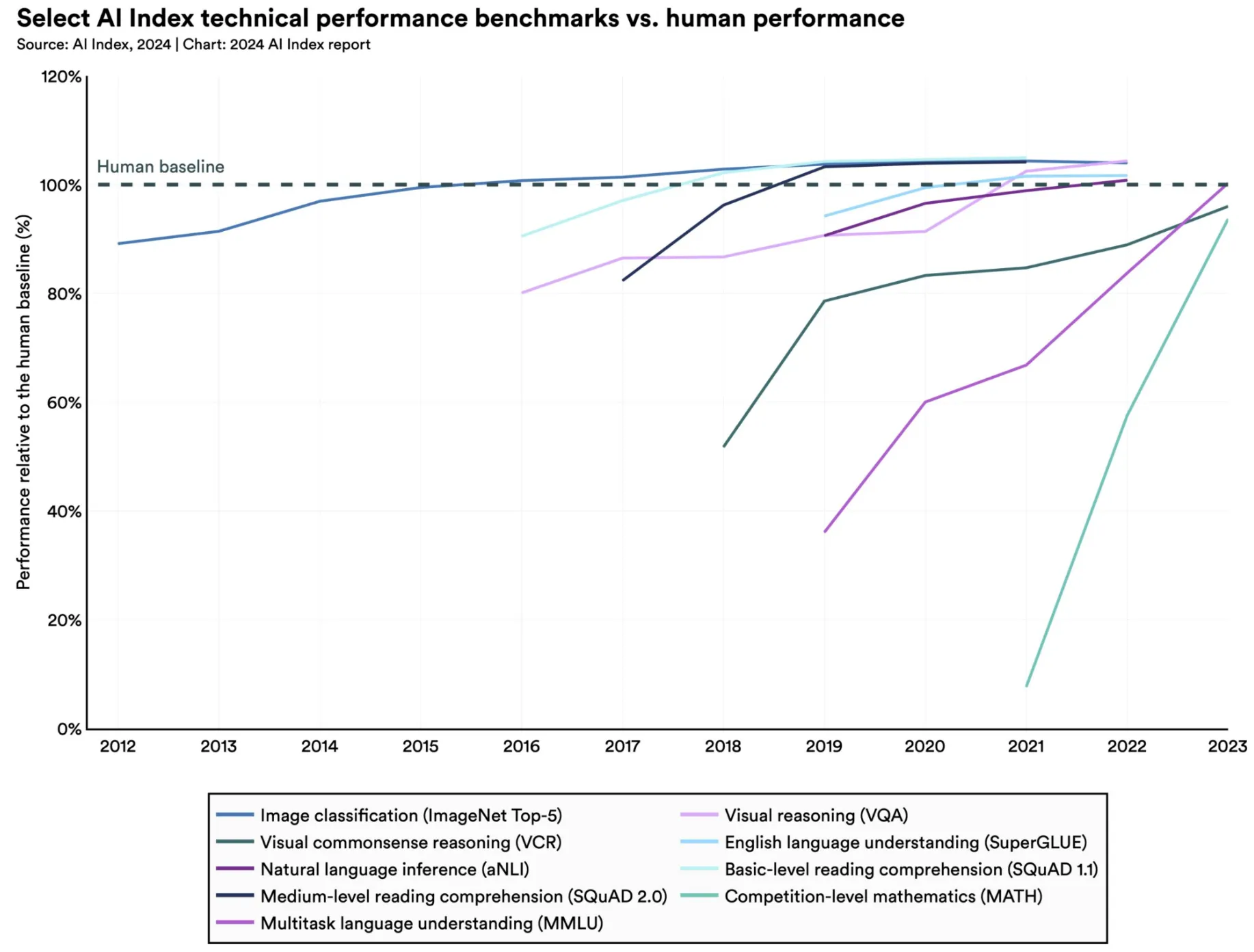
AI is getting good. Really good, in fact. Stanford’s 2024 AI Index Report shows that AI has surpassed human performance on several benchmarks, including some in image classification, visual reasoning, and English understanding.
This has led to a surge in the demand for ML and AI, forcing many data teams to reprioritize their work. It’s also left the question of the data team’s role in ML and AI unanswered. In our experience, the lines between what’s owned by data and what’s owned by engineers are still blurred.
“We have a ratio of 3 to 1 machine learning engineers per data scientist highlighting the share of work that it takes to go from a prototype to a model that works in production” – Chief Data Officer, UK Fintech.
dbt recently surveyed thousands of data practitioners, shedding light on data teams’ involvement in AI and ML.
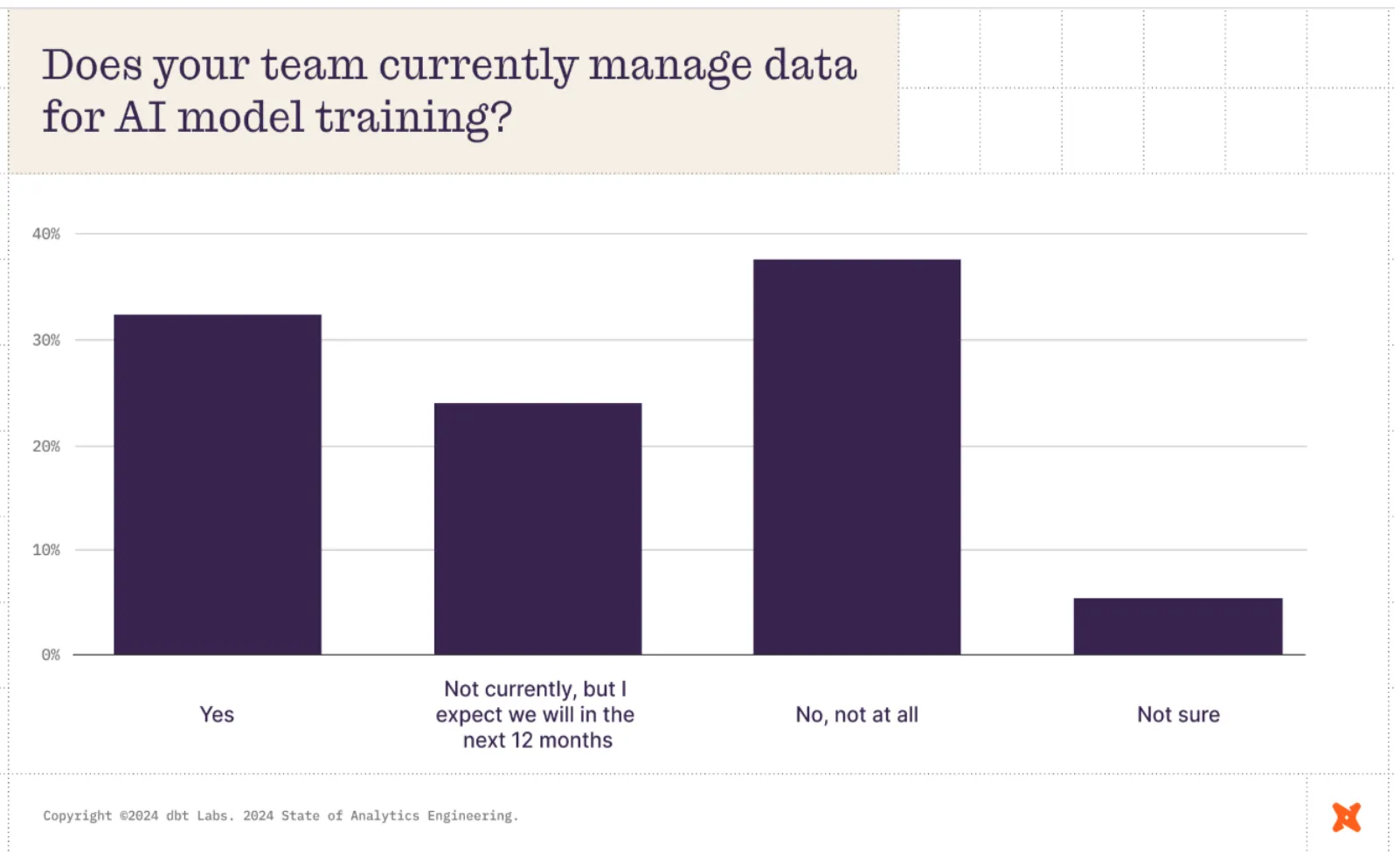
There are signals of AI adoption, but most data teams are still not using it in their day-to-day work. Only a third of respondents currently manage data for AI model training today.
This may change soon. 55% soon expect AI to reap benefits for self-serve data exploration—among other use cases.
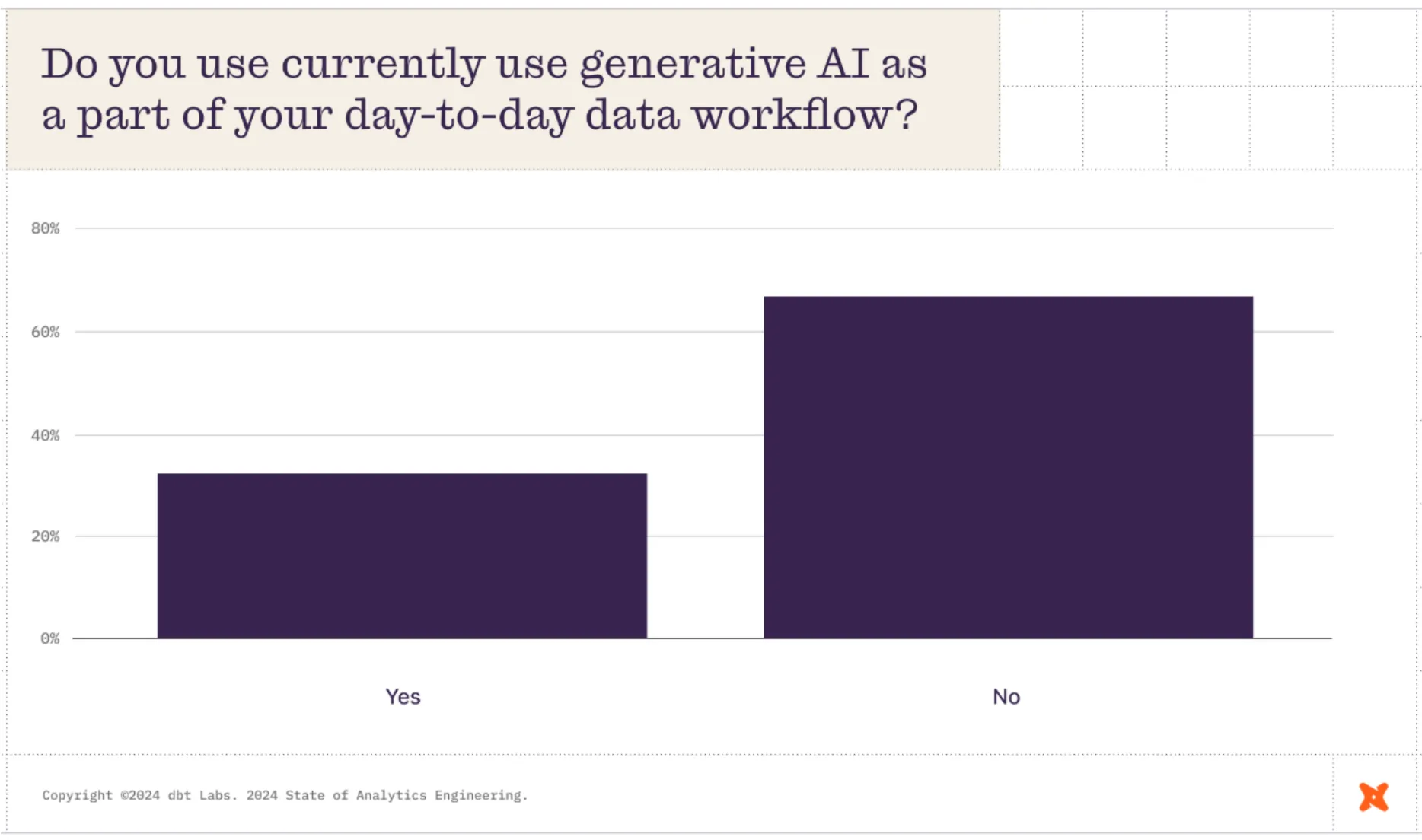
This reflects our experience from talking to more than a thousand data teams. Current efforts are concentrated mainly on preparing data for analysis, maintaining dashboards, and supporting stakeholders, but the desire to invest in AI and ML is there.
AI and ML use cases
Although it may not seem so, ML and AI have existed for decades. While Gen AI models may be best suited for cutting-edge use cases such as generating SQL code from text or automatically answering business questions, more proven methods such as classification and regression models serve a purpose, too.
Below are some of the most popular techniques.
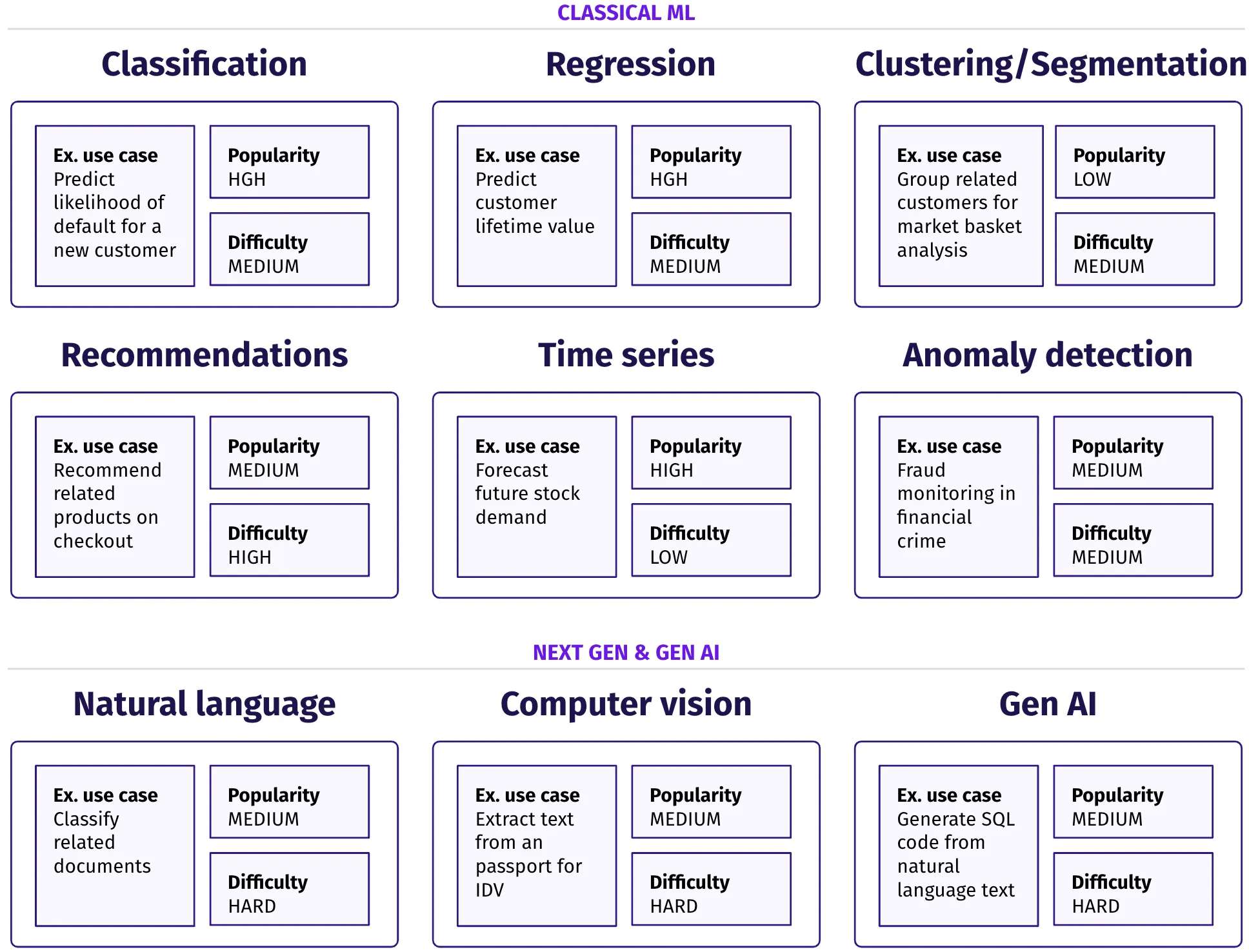
Classical ML use cases
Most teams still do not use traditional ML, such as classifications, regressions, and anomaly detection. These methods can be powerful, especially for supervised learning where you have a clear outcome you want to predict (e.g., risky customer) and predictive features (e.g., signup country, age, previous fraud). These systems are often easier to explain, making it possible to extract the relative importance of each feature, helping explain to stakeholders why a decision to reject a high-risk customer was made.
The ML system below highlights a customer risk scoring model that predicts how likely it is that new sign-ups are risky customers and should be rejected.
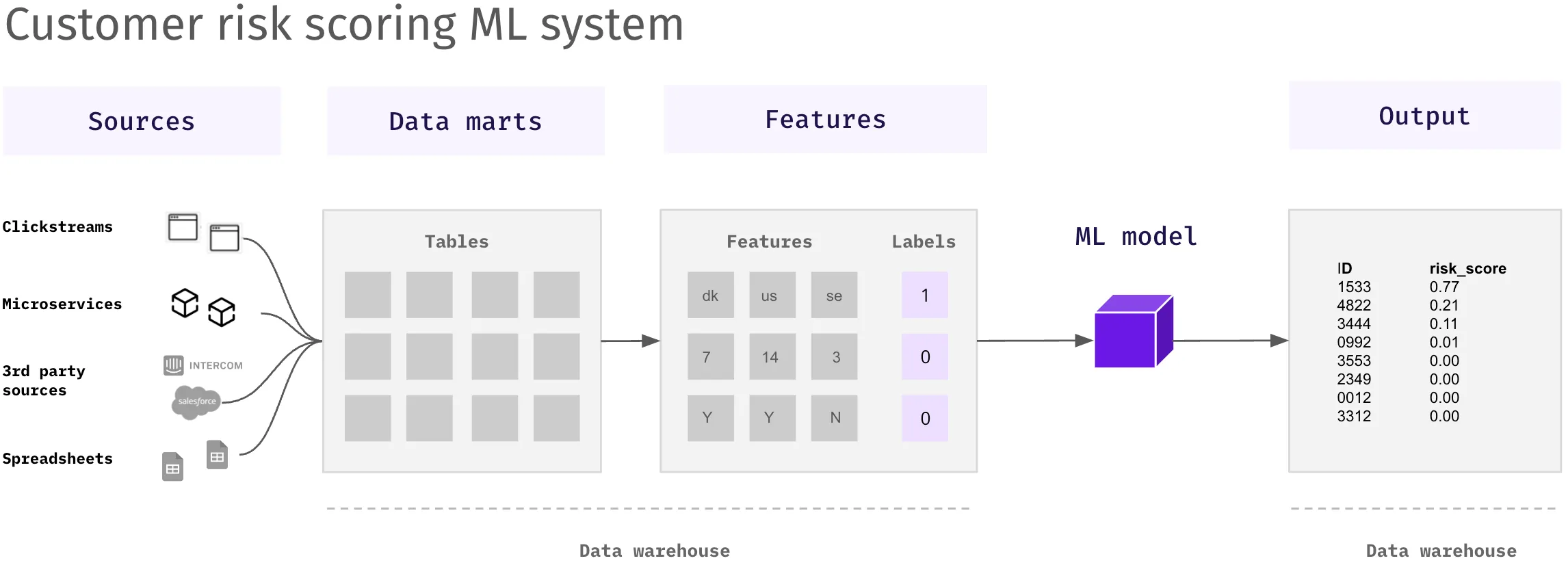
Raw data is collected from different sources and used to build predictive features, combining the data scientist’s domain expertise with unexpected patterns the model identifies. Key concepts are:
- Sources & data marts – raw and unprocessed data extracted from the system deemed to be relevant by the data scientist
- Features – preprocessed data that are fed into the ML model (e.g., distance of a large city, age, previous fraud)
- Labels – target outputs based on previous risky customers (yes/no)
- Training – the iterative process of teaching a machine learning model to make accurate predictions by adjusting its internal parameters or weights based on labeled examples
- Inference – using the trained machine learning model to make predictions or classifications on new, unseen data after the training phase
From our work with data teams, we see a larger part of the classical ML workflow moving to the data warehouse, serving as the backbone for data sources and feature stores. Major data warehouses have started integrating this directly in their offering (e.g., BigQuery ML), hinting at a future where the end-end ML workflow moves entirely to the data warehouse. Read more in our article: Building reliable machine learning models in the data warehouse.
Typical challenges for the success of classical ML models are:
- Can the model predict the desired outcome with the right level of accuracy and precision given the data that’s available
- Is the ROI to the business of the achieved levels of accuracy and precision sufficient
- What’s the trade-off we have to make to make this work (e.g., more operational people to review risky customers)
- What’s the upkeep in maintaining and monitoring the model
Next-gen and Gen AI use cases
Next-gen, and particularly Gen AI use cases, have been the talk of the town the last few years and have been made popular because of the effectiveness of ChatGPT 3. While the space is new and business ROI is still to be proven, the potential is huge.
Below are some of the most popular Gen AI use cases we’ve seen for data teams.
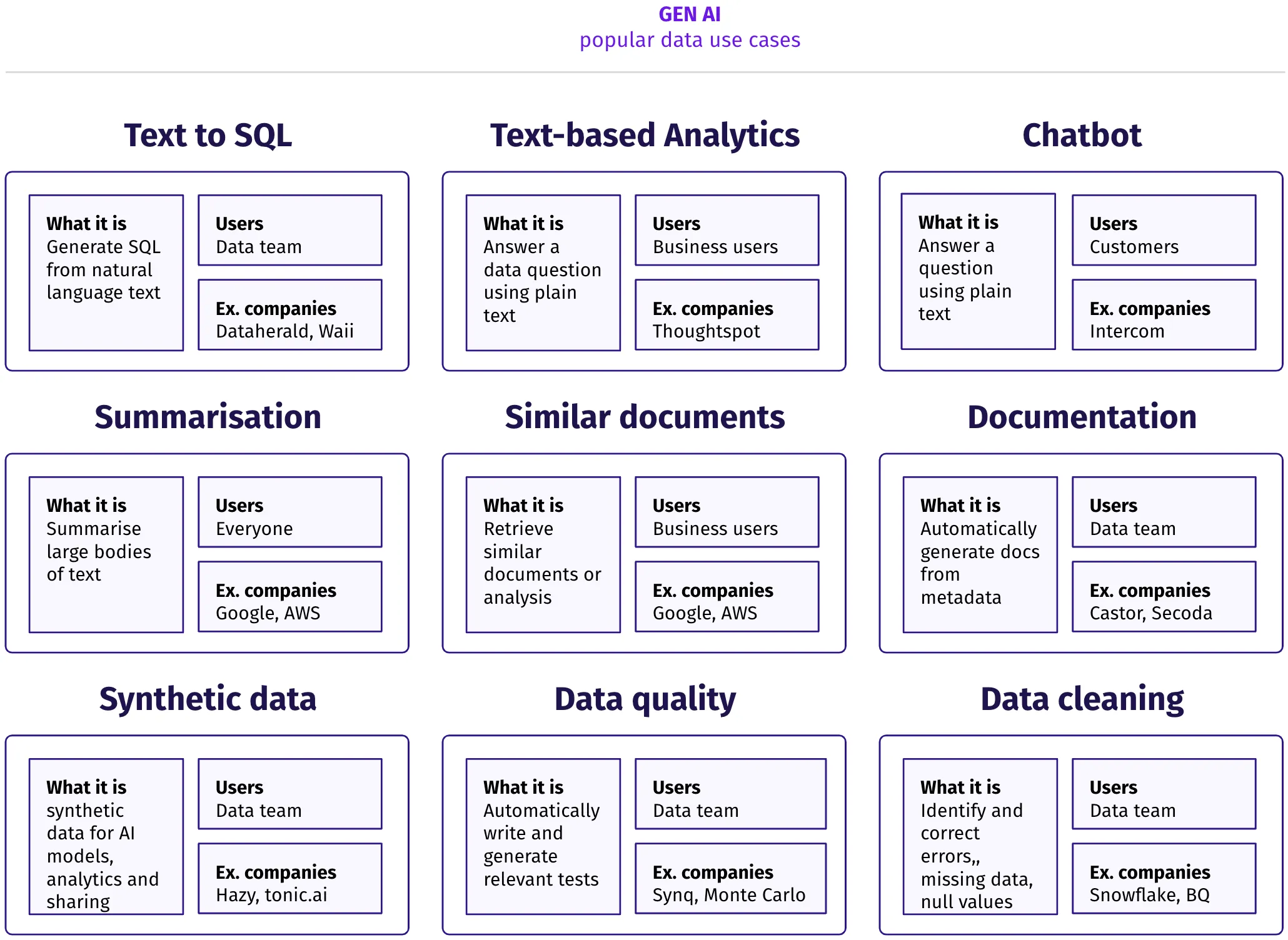
Today’s use cases can broadly be grouped into two areas.
- Business value gains—Automate or optimize a business process, such as automating simple customer interactions in a customer support chatbot or matching customer answers to related knowledge base articles.
- Data team productivity gains–Simplify core data workflows, enabling less tech-savvy analysts to write SQL code with ‘text to SQL’ or reducing ad hoc requests from business stakeholders by generating answers from natural language questions.
Below is a sample architecture for setting up your own version of ChatGPT over a specific corpus of data relevant to your business. The system consists of two parts: (1) data ingestion of your domain data and (2) querying the data to answer questions in real-time.
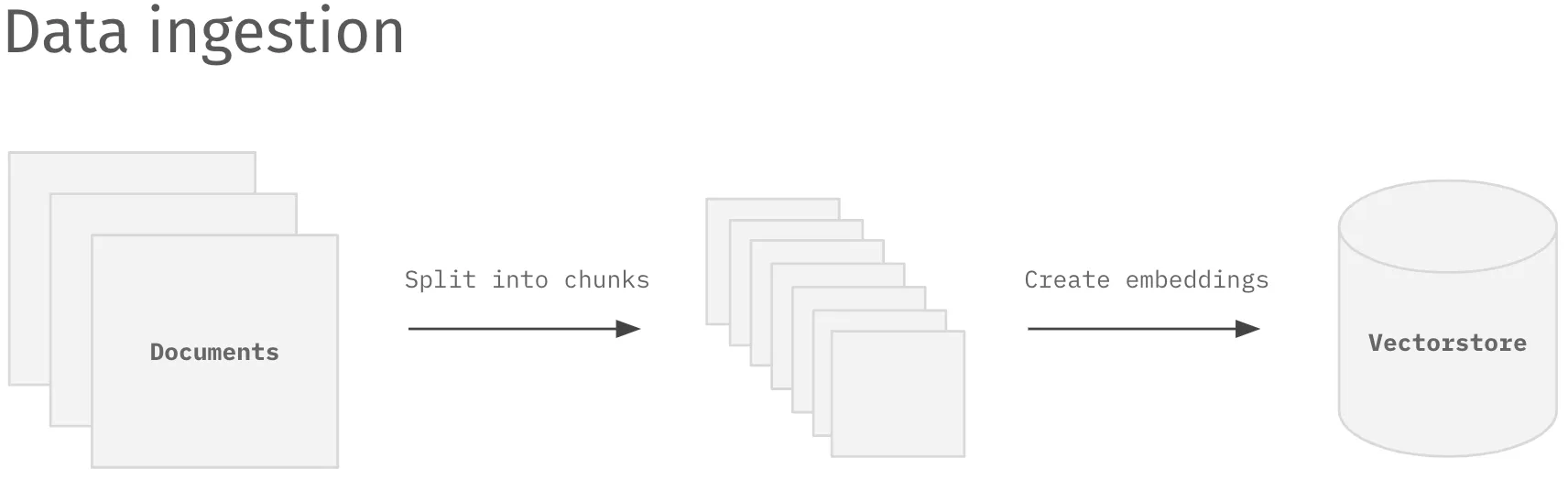
The first step is loading your documents into a vector store. This may include combining data from different sources, working with engineers on raw exports, and manually removing data that you don’t want the model to train on (e.g., support answers with low customer satisfaction)
- Load data sources to text from your specific text corpus
- Preprocess and chunk text into smaller bites
- Create embeddings to create a vector space of words based on their similarity
- Load embeddings into a vector store
If you’re unfamiliar with embeddings, they are numerical representations of words or documents that capture semantic meaning and relationships between them in a high-dimensional vector space. If you run the code snippet below, you can see what it looks like in practice.
from gensim.models import Word2Vec
# Define a corpus of sentences
corpus = [
"the cat sat on the mat",
"the dog barked loudly",
"the sun is shining brightly"
]
# Tokenize the sentences
tokenized_corpus = [sentence.split() for sentence in corpus]
# Train Word2Vec model
model = Word2Vec(sentences=tokenized_corpus, vector_size=3, window=5, min_count=1, sg=0)
# Get word embeddings
word_embeddings = {word: model.wv[word].tolist() for word in model.wv.index_to_key}
# Print word embeddings
for word, embedding in word_embeddings.items():
print(f"{word}: {embedding}")Once you’ve ingested your domain data into the vector store, you can extend the system to answer questions related to your domain by fine-tuning a pre-trained LLM.
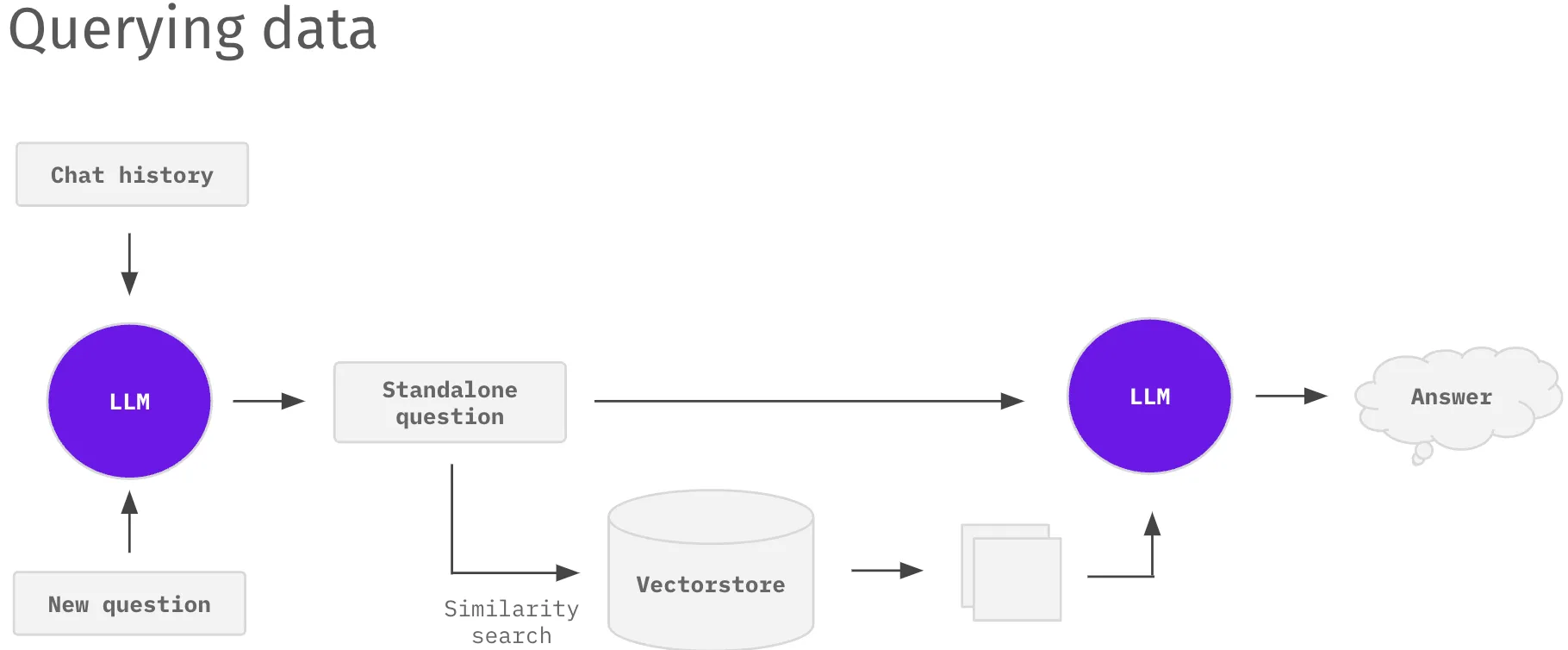
- The user can ask follow-up questions by combining the chat and the new questions.
- Using the embeddings and the vector store from above, find similar documents.
- Generate a response using similar documents using the large language model such as ChatGPT.
Luckily, companies like Meta and Databricks have trained and open-sourced models you can use (Huggingface currently has 1000+ Llama 3 open-source models). So you don’t have to spend millions of dollars training your own. Instead, just fine-tune an existing model with your data.
The effectiveness of LLM-based systems, such as the one above, is only as good as the data they’re being fed. Therefore, data practitioners are encouraged to feed as much data as possible from various sources. A top priority should be to trace where these sources come from and whether data flows as expected.
Typical challenges for the success of Gen AI models are:
- Do you have sufficient data to train a model that’s good enough, and is some data off-limits due to privacy concerns
- Does the model need to be interpretable and explainable to, e.g., customers or regulators
- What are the potential costs of training and fine-tuning the LLM? Do the benefits outweigh those costs?
The importance of data quality in AI and ML
If your primary data delivery is producing ad-hoc insights or data powering BI dashboards for decision-making, there’s a human in the loop. Due to human intuition and expectations, data issues and unexplainable trends are often caught—and most likely within a few days.
ML and AI systems are different.
It’s not uncommon for ML systems to depend on features from hundreds or even thousands of different sources. What may look like simple data issues – missing data, duplicates, null or empty values, or outliers – can cause business-critical issues. You can think about these in three different ways.
- Business outages—A critical error, such as all user_ids being empty, can cause a 90% drop in the new user signup approval rate. These types of issues are costly but often spotted early.
- Drift or ‘silent’ issues–These can involve a change in customer distribution or a missing value for a specific segment, which causes systematically incorrect predictions. They are hard to spot and may persist for months or even years.
- Systematic bias–With Gen AI, human judgment or decisions on data collection can cause bias. Recent examples, such as biases in Google’s Gemini model, have highlighted the consequences this can have.
Whether you’re supporting a regression model or building a new corpus of text for an LLM, unless you’re a researcher developing new models, chances are that the bulk of your work will evolve around data collection and preprocessing.
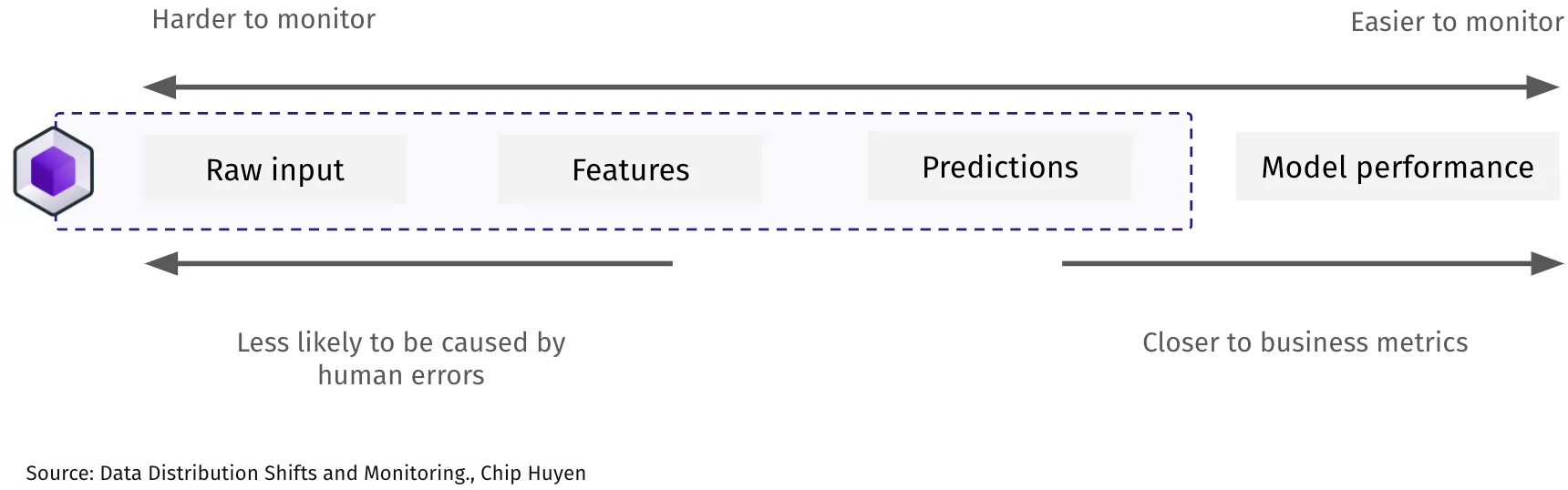
“You’re so far downstream as the ML team. Almost any upstream issue will impact us, but we’re often the last to know.” – Mobility scaleup.
As a rule of thumb, the further to the left you are, the harder it is to monitor for errors. With hundreds of input and raw sources, often outside the data practitioners’ control, data can go wrong in thousands of ways.
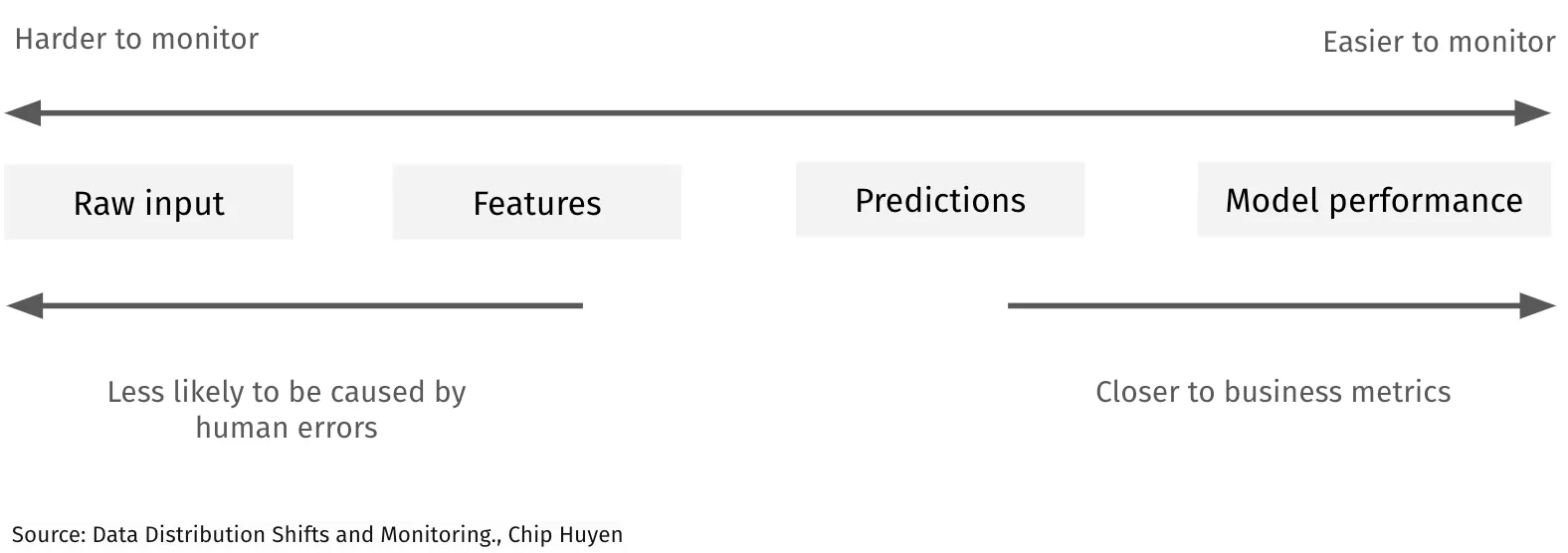
Model performance can more easily be monitored with well-established metrics such as ROC, AUC, and F1 scores, which give you a single-metric benchmark of your model’s performance.
Examples of upstream data quality issues
- Missing data: Incomplete or missing values in the dataset can impact the model’s ability to generalize and make accurate predictions.
- Inconsistent data: Variability in data formats, units, or representations across different sources or over time can introduce inconsistencies, leading to confusion and errors during model training and inference.
- Outliers: Anomalies or outliers in the data, significantly different from most observations, can influence model training and result in biased or inaccurate predictions.
- Duplicate records: Duplicate entries in the dataset can skew the model’s learning process and lead to overfitting, where the model performs well on training data but poorly on new, unseen data.
Examples of data drift
- Seasonal product preferences: Shifts in customer preferences during different seasons impact e-commerce recommendations.
- Financial market changes: Sudden fluctuations in the market due to economic events impacting stock price prediction models.
Examples of data quality issues with text data for an LLM
- Low-quality input data: A chatbot relies on accurate historical case resolutions. The bot’s effectiveness depends on the accuracy of this data to avoid misleading or damaging advice. Answers with a low customer satisfaction or resolution score can indicate that the model may have learned the wrong information.
- Outdated data: A medical advice bot may rely on outdated information, resulting in less relevant recommendations. Research created before a specific date may indicate that it’s no longer fit for purpose.
Building reliable ML and AI systems
At Synq, we believe that data teams are not trusted to deliver reliable data systems compared to their counterparts in software engineering. The AI wave is exponentially scaling the “garbage in, garbage out” model and all its implications – when every company is under pressure to find new ways to activate data for competitive advantage.
“In the past few years, data has become more important to more companies than ever before. However, how data infrastructure is built, and the tools with which data reliability is managed have lagged. The result is a reliability gap at the heart of organizations with business-critical data.” – Petr Janda, CEO of Synq.
While there are specific tools and systems to monitor model performance, these often don’t consider upstream sources and data transformations in the data warehouse. Data reliability platforms such as Synq are built for this.
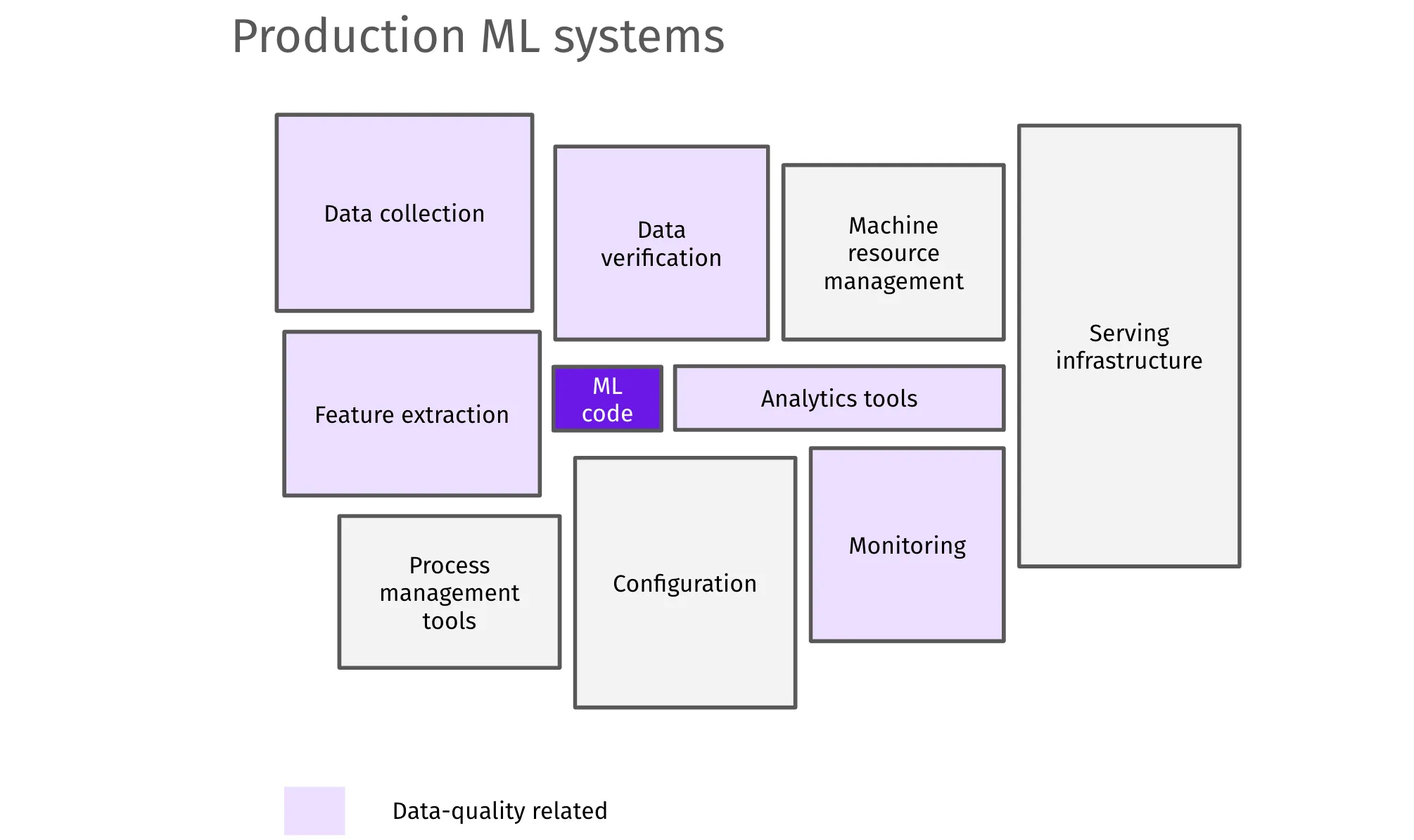
The five pillars to building reliable ML and AI systems
To support and maintain high-quality production-grade ML and AI systems, data teams must adopt best practices from engineers.

- Diligent testing – upstream sources and outputs feeding into ML and AI systems must be intentionally tested (e.g., outliers, null values, distribution shifts, and freshness)
- Ownership management – ML and AI systems must have clear owners assigned who are notified of issues and are expected to act
- Incident process – severe issues should be treated as incidents with clear SLAs and escalation paths
- Data product mindset – the entire value chain feeding into ML and AI systems should be considered as one product
- Data quality metrics – the data team should be able to report on key metrics such as uptime, errors, and SLAs of their ML and AI systems
Just focusing on one of the pillars is rarely sufficient. Issues may slip through the cracks if you over-invest in testing without clear ownership. If you invest in ownership but do not intentionally manage incidents, severe issues may go unsolved for too long.
Importantly, if you succeed in implementing the five data reliability pillars, it doesn’t mean you won’t have issues. But it means you’re more likely to proactively discover them, build confidence, and communicate to your stakeholders how you’re improving over time.
Summary
While only 33% of data teams currently support AI and ML models, most expect to in the near future. This shift means data teams must adjust to a new world of supporting business-critical systems and work more like software engineers.
- State of AI in data teams–AI systems are improving, with several benchmarks such as image classification, visual reasoning, and English understanding surpassing the human-level benchmark. 33% of data teams currently use AI and ML in production, but 55% of teams expect to.
- AI use cases—There are a wealth of different ML and AI use cases, ranging from classification and regression to Gen AI. Each system poses challenges, but the difference between “classical ML” and Gen AI is stark. We looked into this through the lens of a classical customer risk prediction model and an information retrieval chatbot.
- Data quality in AI and ML systems–Data quality is one of the most significant risks to the success of ML and AI projects. With AI and ML models often relying on hundreds of data sources, manually detecting issues is nearly impossible.
- The five steps to reliable data–To support and maintain ML and AI systems, data teams must work more like engineers. This includes diligent testing, clear ownership, incident management processes, a data product mindset, and being able to report on metrics such as uptime and SLAs.

.png)
.png)